Collation on the Web
July 18, 2013, 10:30 | Short Paper, Embassy Regents F
Collation comes from the Latin confero (perfect participle collatum) meaning ‘bring together’. There are several meanings in English, among them ‘bring together for comparison … in order to ascertain points of agreement and difference’ (OED, 2012). Even here collation may refer to a mechanical, manual or computerised process of comparing texts. My focus is on the latter, because it derives from an originally manual process as described, for example, by West (1973, 66f) and Dearing (1962, 14ff). Collation was a key part of the preparation of a critical edition because it supplied the raw differences between a chosen copy text and the other versions that aided the establishment of a single text suitable for printing.
Vinton Dearing in 1962 described what is perhaps the world’s first collation program (1962, 18-19). It compared two texts, one line at a time, within a window of 10 lines in either direction. Once a line (or later a word) was matched in the two versions being compared, the window was moved on. This allowed it to recognise insertions, deletions, substitutions and transpositions over short distances. The window was used probably because memory on the IBM 7090 for which it was written, was limited. This basic design was then followed in all subsequent collation programs. For example the collation program of Froger (1968 234), ‘EDIT’ (Silva and Bellamy 1969, 41-25), ‘OCCULT’ (Petty and Gibson 1970), the collation program of Gilbert (1973), ‘UNITE’ (Marín 1991), ‘PC-CASE’ (Shillingsburg 1996, 144-148), ‘TUSTEP-Collate’ (1979), ‘URICA!’ (Cannon and Oakman 1989), ‘DV-Coll’ (Stringer and Vilberg 1987) and ‘Collate’ (Robinson 1989, 1994) all appear to use the same ‘sliding window’ technique. The size of the window varies, and in various programs extra features are added such as the ability to embed references, define transposed blocks and perform spelling normalisation (Collate), or the ability to merge collation output from each run (TUSTEP, PC-CASE).
One point often mentioned in these early collation programs is that they were developed to automate the manual process of producing a print edition. As Cannon explains: ‘automatic collation should proceed as it would be performed manually’ (1976, 33). Robinson also admits, when talking of the automatic treatment of variants that ‘most electronic editions do the same as book editions: they just do more of it, perhaps with marginally more convenience’ (2003).
The sliding window technique has come to define what automatic collation is, but it has some serious technical limitations. For example, it cannot see alignments of words outside of the window, and this makes it prone to mistakes, which must be manually corrected. However, modern computers have no need of a window, as they can easily load into memory the entire text for comparison.
One may also ask whether a print-based collation technique is really suited to a modern fluid medium like the Web. Differences discovered by a machine are not always suitable for display on a screen. As Robinson points out: ‘Some differences will be just, well, noise: only a few ... are real variants, of real interest to real scholars.’ (2009, 349). Hence all the early collation programs employ filtering, whether some kind of fuzzy matching, or a normalisation table to discount minor spelling variants. However, an apparatus generated in this way cannot subsequently be recombined with the base text to produce the faithful text of another version, because after filtering it contains only a tiny fraction of the true differences. It thus can only be attached to a base version as a series of notes, which limits the possibilities for display and interaction between user and text.
Another problem arises from the use of embedded markup. When SGML and then XML became popular from around 1990, there was a notable decrease of interest in collation programs. Existing programs were not updated, and replacements that fully handle XML have not yet emerged. The reason seems to be that if the computed differences between two texts contain disconnected start or end-tags, how does one supply the missing tags? In the case of an apparatus entry generated from TEI-XML such as: ‘word</hi>’, what is the format of ‘word’? It could be anything because the start-tag and its attributes have been lost. So markup must be stripped out before collation can take place, as is done, for example, in Juxta Commons (2012). But stripping out markup is prone to error: how, for example, does one deal with embedded notes, and interpretations, or alternatives like ‘sic’ and ‘corr’ or embedded variants? (Schmidt 2012a). It also makes it difficult to compare formatting differences, and to later restore the markup, because the differences only refer to the stripped text.
A further problem is whether people really want to see a print apparatus on the screen. Although it may be defended as a traditional form of variant display, what the modern user ultimately wants is interactivity. The essence of the modern Web is animation or the ability to edit and contribute in real time, not statically formatted data.
From collation to merging
What is needed for the medium of the Web is a thorough reassessment of the collation process. As a first step the difficulties in comparing embedded markup can be avoided by separating the text from its properties. ‘Standoff properties’ (Schmidt 2012a), which are modelled on LMNL (Piez, 2010), can be used in place of embedded XML, and may be generated from plain text or XML files. For each version this produces one version of the text and one or more markup files. The text and markup can then be merged separately, using the nmerge program (Schmidt 2009), into multi-version documents, which record the differences between all the versions globally – not merely between the base version and the rest. Because it doesn’t use a sliding window, but looks for differences over the entire text, nmerge doesn’t lose its way. The separately computed differences in the markup and the text are merged with the text’s own structural properties and then formatted into HTML, without the need for XML. This new platform for digital editions facilitates various techniques for displaying variation (Figure 1). Each display is generated as a partial web-page so it can be incorporated into any kind of Web-delivery system:

Figure 1:
Collation workflow using MVD+standoff properties
The most popular of these is the side-by-side display. Examples include MEDITE (Bourdaillet and Ganascia 2006), the MVD-GUI (Schmidt et al. 2008), Juxta Commons (2012), the Trein der Traagheid electronic edition (Roelens et al. 2012), the Versioning Machine (Schriebman 2011), etc. Some of these programs have synchronised scrolling, which helps keep compared versions in alignment. Side by side view is more suited to programs like MEDITE or nmerge that compute character-level differences as opposed to word-level differences, because the user can see at a glance how two similar words differ. And multi-version documents already contain all the differences between versions, which don’t need to be recomputed each time, resulting in a much faster response, as can be seen in the AustESE (Australian electronic scholarly editions) test web interface (Schmidt 2012b).
Another popular type of variant display is the table, as found in CollateX (Dekker et al. 2011), and in the Cervantes hypertext edition (Urbina 2008). This is particularly useful in textual criticism because it presents much the same information as the old apparatus, but in a native digital form. In the AustESE test interface, table view (Figure 2) offers several options to reduce variant clutter without resorting to filtering. Character-level granularity can be easily extended to word-level, which is more useful for this type of display. Table view has the advantage over side-by-side in that it allows the user to explore the differences between a larger set of versions. Combining a horizontally scrolling table of variants with a synchronised vertically scrolling main text even produces a credible replacement for the print critical edition in digital form (Schmidt 2012b).
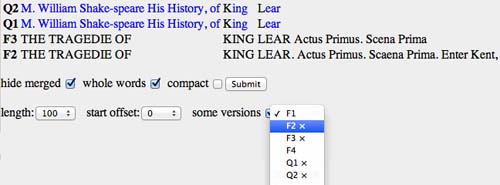
Figure 2:
Table view
Conclusion
The goal of collation on the Web is to provide the user with a variety of display options for exploring variation in a work. Collation conceived as a process for producing an apparatus or a filtered set of differences external to the text is too limited a technique to satisfy the flexible delivery options of the Web. Merging variant versions into a single digital object, on the other hand, provides a more efficient and direct way to query differences between versions, and to present the results through various views. Embedding markup into the text also creates problems for collation, and its removal allows differences between versions of text and markup to be merged as separate layers into the final result. The medium of the Web thus offers more than just new ways to display old data. It challenges us to rethink fundamentally the way we create the modern edition.