Text to Image Linking Tool (TILT)
July 19, 2013, 10:30 | Long Paper, Embassy Regents C
The digital edition has long been conceived not only as a set of transcriptions of the witnesses that underlie a work, but also as the images of the manuscript and book pages that physically represent it. Showing a readable transcription next to the facsimile of its source document provides the reader with the same level of evidence enjoyed by the editor of a print edition.
Connecting ranges of text to areas in the image is useful wherever a manuscript has been heavily corrected or was written long ago in a writing style now hard to decipher. Even for printed works, the absence of such links forces the reader to waste time scanning the facsimile whenever the layouts differ, spelling variations have been regularised, or the text emended (Kiernan, 2006). Establishing text-image links was first explored in the electronic Beowulf edition (Dektyar et al., 2004). Other examples include the British Museum’s electronic Codex Sinaticus (2009) and, using a different display technique, the ‘zoom topographic’ view of the Samuel Beckett digital manuscript project (Van Hulle et al., 2011). But the technical requirements of providing this form of interaction for any digital edition are considerable. There are three main problems:
- 1. How to display text-image links at the line and word-level over the Web
- 2. How to edit and automate the creation of links
- 3. How to store them in a reusable and efficient form
1. Viewing links
As a solution to problem 1 a background image (Figure 1c) is overlaid first by a transparent pane or canvas on which drawing is done (b), and second by a set of invisible areas (a) that trigger simultaneous highlighting in the text and image as the mouse moves over them (Schmidt, 2012c). Polygonal areas are needed, since in many cases, e.g. curved or slanted lines, corrections, inserted text-blocks etc. rectangles are simply too imprecise. It is also versioned: the highlighted areas change according to the version of the text (base or corrected) chosen on the right.
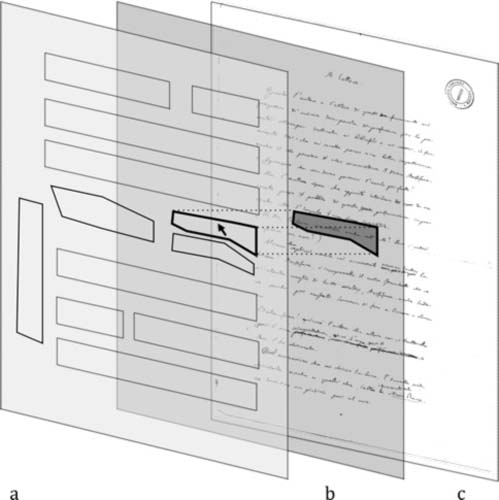
Figure 1: Web visualisation of image areas
In an alternative technique described by Cayless (2008), images of the text are converted to SVG surrogates (an XML format), and their bounding rectangles computed, to facilitate linking with the XML-encoded text. However, this increases the overall complexity of the encoding, and invites overlap between existing markup and the newly added spans. The solution described here, on the other hand, requires only simple features of HTML5, and is more amenable to automation.
2. Creating and editing links
There have been several tools already developed for creating and updating links from areas in a facsimile to spans in a transcription. This operation should be distinguished from more general kinds of image annotation, because text-image links are far more numerous, more specialised and, as Kiernan notes (2006b), likely to overwhelm any standard annotation system.
There appear to be only three tools that meet this narrow definition. The first is EPPT, created for the electronic Beowulf edition (Iacob and Kiernan, 2009) as part of the ArchWay project (Kiernan et al, 2005). This was an Eclipse plug-in (a programmer’s tool) that created simple shapes without automation. The Textgrid TBLE tool is likewise an Eclipse plug-in (Al-Hajj, 2011). Although it does not yet support automation, it can draw polygons. However, having the editing tool available over the Web would facilitate updating through scholarly collaboration and crowd-sourcing (e.g. ANL, 2012). TILE (Reside et al., 2009) is so far the only Web-based solution to the text-to-image editing problem, but it remains incomplete.
Our need was for an immediate solution for both print and manuscript texts so we could begin entering data for projects like the Charles Harpur archive (SETIS). This is a collection of large manuscript anthologies (100-350 pages) and newspaper cuttings. Thus, to be practical, the text to image linking process would have to be largely automated. Our program was designed as an applet (a Java web plug-in) because this allows for rapid and stable development, support for image analysis, and Web presentation. It is called TILT (text-image linking tool) because it is designed to deal with moderately curved or slanting text (Schmidt 2012b). This is frequently found in facsimilies due to the difficulty of laying books or manuscripts absolutely flat, and also in manuscripts where the text is written in crooked lines or at an angle. TILT uses automation at several levels:
- 1. Auto-recognition of pages at the word or line-level
- 2. Auto-outlining of individual lines in response to a click or tap
- 3. Auto-outlining of individual words similarly
- 4. Manual drawing of polygons and rectangles
- 5. Automatic linking of the current shape to the text
Word recognition
When the user clicks on a word, a small square is assessed around the click-point (Figure 2). If the darkness of this square exceeds the average document darkness it is accepted (solid outlines, left). Adjacent squares are assessed similarly. If a square fails the test it is subdivided into four. If any one of these smaller squares is accepted then adjacent full-size squares are assessed as before. Otherwise it is discarded (dotted outlines, left). This leads to a rapid determination of word-boundaries. The basic outline is then converted into a bounding box (solid outline, right), or if this is too wasteful, into a polygon (dotted outline, right).
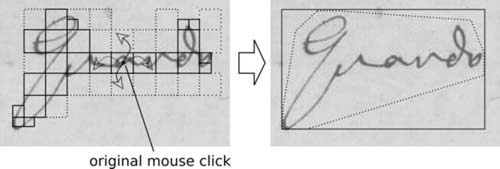
Figure 2: Detection of word boundaries
Line recognition
To facilitate line-recognition, the facsimile, which is often in colour, is first reduced to grayscale, then to pure black and white by application of a localised contrast filter, which erases differences caused by uneven lighting.
Baselines of the text can be found by summing the pixels in each horizontal row of the image. Rows with peak pixel-counts exceeding the average background darkness may be interpreted as baselines. These can be further constrained to lie within the text block, and only where there is surrounding text. The user can see the detected baselines by clicking the Lines tool. To detect entire lines the word-detection algorithm is simply applied along each baseline. To detect slanted or wavy baselines the image could be vertically divided into strips, and the lines in each strip joined up, although this is not yet implemented.
Linking word-shapes to the text
Word-shapes detected in the image are allocated approximately to corresponding word-positions in the text. Although breaking up the text into lines will make this more accurate, manually specifying positions where words and shapes do in fact match will allow this approximation to be gradually refined. Thus it is expected that, in practice, little human intervention will be needed to connect all word shapes to their correct words. For well laid-out facsimilies, e.g. of printed books, whole page recognition may be sufficient to link everything in one go.
3. Storing links
There have been several proposals for recording the data of text-image links. The model described by Audenart and Furuta (2009) focuses on the images rather than the work, whereas for our needs the latter is primary. The markup schemes described by Dekhtyar et al. (2005), and in TEI P5 (22.3) are based on embedded XML. As Kiernan (2006b) notes, text to image links, if embedded in the text, usually overlap with any markup already present. The resulting mixture of milestones and ordinary tags can be very complex.
On the other hand, simply using standoff properties (Schmidt 2012a), which are based on LMNL (Piez, 2010), to record the links, would simplify things considerably. Although saving is not yet implemented in TILT, each link, consisting of a shape and a textual span, could be saved as a separate layer. Links could then be merged with the other markup in the text, or used to generate the map which overlays the image (Figure 1a).
Conclusions and future work
The most important goal of TILT will be the testing of user requirements, which can only happen once a practical tool has been built. For example, how to deal with line-breaks in the middle of words, and what level of granularity (word or line) will work best must still be determined. TILT still lacks essential features like zooming, saving, the ability to change images as the user scrolls through the text, and export to other formats. However, based on current progress it is anticipated that these features will be completed by July 2013. There seems to be a pent-up demand for a text-image linking tool like this, given the current interest in digital facsimiles and the general exploration of more interactive interfaces for digital editions.