Surveying a Corpus with Alignment Visualization and Topic Modeling
July 17, 2013, 15:30 | Centennial Room, Nebraska Union
With the advent of sophisticated computational tools for analyzing large corpora of literary texts, scholars have proposed a variety of terms to describe what they do when they use these tools. Text data mining (Hearst), distant reading (Moretti), algorithmic criticism (Ramsay), assisted reading (Schmidt), hyper reading (Hayes), faceted search (Whaling), scalable reading (Mueller): these seek to capture a shift in how digital technology allows readers to observe patterns within texts and to use the findings to inform a closer reading. N. Katherine Hayes summarizes the affordances of computational tools as methods of scanning, which quickly seek specific words within texts, and methods of skimming, which attempt to get a rapid sense of what texts are about (61). Scanning is best served by text retrieval, whereas skimming requires techniques like corpus queries and topic modeling.
To add to the lexicon of digital text analysis, I propose the idea of surveying a corpus using a combination of text retrieval for scanning and data visualization for skimming. Stan Rucker, Milena Radzikowska and Stéfan Sinclair have articulated a theory of data visualization based on the notion of prospect, “a view of the world where enough information is available for the perceiver to understand the terrain and have a sense of what it affords, without necessarily seeing all the details” (26). Surveying a corpus relies on sufficient prospect to enable the reader to see textual information from a distance and to perceive patterns on a scale larger than a single text. The ability to skim a corpus for the purpose of surveying it would ideally allow the reader to easily zoom from a comprehensive view of patterns to specific instances within texts where scanning for specific words may be desired. Conversely, the results of text retrieval searches should be available for constructing corpus queries: if a particular string appears in one or more texts, a reader surveying a corpus may want to get a broader sense of how the string is used without skimming through a long KWIC listing.
To show what I mean by surveying a corpus, I will offer a demonstration of a database built with ARTFL’s Philologic that includes a visualizer for sequence alignments and a topic model browser for ordered lists of documents, words and algorithmically derived topics (see http://bumppo.hartwick.edu/rw/). The corpus is comprised of 181 adventure novels published in French during the nineteenth century. The digital texts were created recently by the Bibliothèque de France using OCR and they contain no markup. Using plaintext documents with minimal metadata, I am able to survey the corpus to get a sense of its themes, recurrent rhetorical devices, innovators, and imitators. This approach is proving particularly helpful for studying a corpus that has received relatively little critical attention. It does not require significant resources for text preparation, and it allows for exploring an obscure corpus to determine if further research is warranted.
I first identified sequence alignments among texts in the corpus using ARTFL’s Philoline module for Philologic. Sequence alignment is the identification of common n-grams shared between two or more documents (Horton et al). The technique, developed for DNA analysis and plagiarism detection, identifies segments of text that have been “borrowed” or reproduced from one document to another. The alignment visualizer, based on an implementation of Danny Holton’s hierarchical edge bundling algorithm and built with Michael Bostock’s D3 JavaScript library, displays texts as a circle of nodes with edges indicating which texts share common passages (Fig. 1).
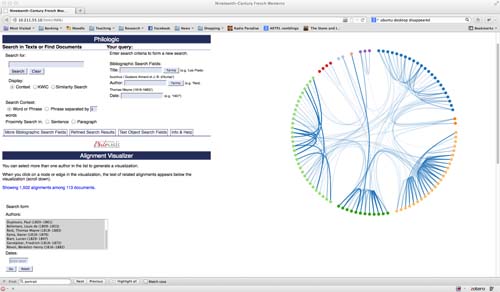
Nodes are grouped by author, and authors are distinguished by colors. The number and thickness of the edges reflect the number of alignments between texts: a node with many edges represents a text that shares alignments with many other texts, and thicker edges mean more alignments between two texts. A “fan” among nodes of a similar color shows numerous alignments among texts by the same author (Fig. 2).

The CSS stroke attribute of edges and nodes changes color when the reader moves the pointer over them (red strokes designate source nodes, green strokes target nodes, blue strokes nodes that are selected by the pointer) (Fig. 3).

The reader can click on an edge or node and immediately examine the associated aligned passages. The selected node in Figure 3 represents Gustave Aimard’s La Grande Flibuste (1860), a text that shares many alignments with other texts by Aimard and five other authors. The graphic suggests that the text is an important one in the corpus, both as a source and target of aligned passages. The visualizer allows the reader to skim the corpus to get a distant view of what it contains. Figure 4 shows two particular alignments between Aimard’s novel and novels by Louis de Bellemare and Mayne Reid. In examining alignments like these, one can contextualize them and get a sense of how La Grande Flibuste is representative of the corpus.

The topic model browser is a JavaScript interface that allows the reader to query the frequencies of documents, words and topics against each other in a corpus. The topics were generated using Andrew McCallum’s Mallet toolkit and then migrated to a MySQL database where each word in each text is assigned to one of fifty modeled topics (Fig. 5).
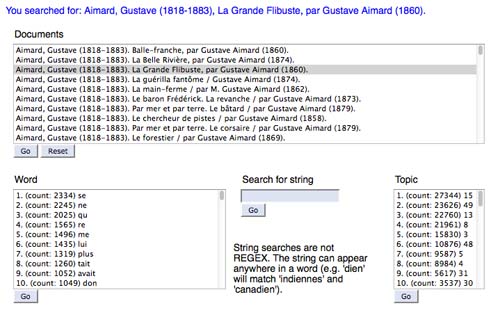
Beginning with a list of documents, the reader can select a text and see lists of words and topics in the text in descending order. From these query results the reader can select any item in any list as the parameter for a subsequent query, which will produce new, ordered lists of documents, words and topics. A basic string search feature (without regular expressions) will also generate ordered lists. In scanning the corpus for words and topics related to La Grande Flibuste, the reader can see how the text relates to other texts and explore the relationships between words and topics.
As prototypes, both the alignment visualizer and the topic model browser are currently limited in their capacity to survey a large corpus. Numerous texts are difficult to represent as bundled nodes in a web browser, and the reader may only be able to skim a subset of the corpus instead of its entirety. My implementation of topic modeling uses the default algorithm for Mallet and does not afford the reader any control over or explanation of the algorithm’s implementation. It also takes a long time to execute queries on a MySQL database of 7,500,000 tokens and their assigned topics. Alternative data structures such as key-value stores may increase speed.
Despite these limitations, the database interface I present here enables the reader to survey a corpus with enhanced prospect. Alignment visualization and topic model browsing offer two methods for skimming a corpus for patterns, which may lead to further insights for interpretation.