"Shall These Bits Live?" Towards a Digital Forensics Research Agenda for Digital Humanities with the BitCurator Project
July 19, 2013, 13:30 | Long Paper, Embassy Regents D
In the title of an important early essay on the intersection of bibliographical method and literary interpretation, Jerome McGann (1988) poses the forensically inflected question: “Shall These Bones Live?” Several decades of subsequent scholarly activity have demonstrated the value of embedding the technical and material concerns of bibliographers and textual critics into the pursuits of mainstream literary studies. Though the rise of born-digital materials—documents and other media types that are created by computer and which circulate primarily or exclusively in “virtual” form—would seem to challenge the relevance of a bibliographic approach to textual studies. In fact, as a number of recent scholars have argued, digital texts themselves exhibit distinct material properties. (Kirschenbaum, 2008; Galey, 2012; Piper, 2012)
This paper seeks to enhance the discussion of digital materiality by exploring in a focused way the specific relevance of digital forensics to digital humanities research. Digital forensics is an applied practice involving the “preservation, identification, extraction, documentation, and interpretation” of digital data as legal evidence (Kruse & Heiser, 2002). We will present examples of all of these activities in the context of the BitCurator project, now concluding its first successful phase of development with funding from the Andrew W. Mellon Foundation. We will demonstrate that digital forensics offers researchers an advanced community of practice around the acquisition, processing, management, and analysis of born-digital objects, and we will suggest that as humanities scholars increasingly engaged with objects of born-digital cultural heritage, digital forensics will emerge as a significant modality within digital humanities. Finally, we will argue that digital forensics offers an especially fruitful area for collaborative research and project development between digital humanities and the digital archives community.
The BitCurator project is a joint effort led by the School of Information and Library Science at the University of North Carolina at Chapel Hill (SILS) and the Maryland Institute for Technology in the Humanities (MITH) to develop an environment for collecting professionals that incorporates the functionality of many existing digital forensics tools. There are, however, two fundamental needs for collecting institutions that are not addressed by software designed for the digital forensics industry: incorporation into the workflow of a colleting institution’s ingest and collection management environments, and provision of public access to the data. BitCurator provides an environment in which users can create forensically-packaged disk images, perform a variety of triage tasks on objects within file-systems, extract and repackage metadata, and redact sensitive information from digital materials.
The BitCurator Environment is a fully functioning Linux system built on Ubuntu 12 that has been customized to meet the needs of librarians and archivists, and can be run as a stand-alone operating system, a virtual machine, or as a set of individual tools (see Figure 1). Development has been informed by consultations with two groups: a Professional Expert Panel (PEP) of individuals who are at various levels of implementing digital forensics tools and methods in their collecting institution contexts, and a Development Advisory Group (DAG) of individuals who have significant experience with development of software. (The membership in these two groups represents many of the key researchers and practitioners currently involved in the archival processing of born-digital materials.) The BitCurator environment incorporates a number of useful digital forensics tools that can easily be integrated into digital curation workflows. A sampling of those tools, all of which are available as public domain or open-source (General Public License) software, includes:
- Guymager: A tool for creating disk images in one of three commonly used disk image formats (dd, E01, and AFF).
- Custom Nautilus scripts: A collection of enhancements to Ubuntu’s default file browser that allow users to quickly generate checksums, identify file types, and safely mount drives, among other tasks.
- The Sleuth Kit: A digital investigation platform.
- fiwalk: An open source tool for processing disk images, producing Digital Forensics XML and human readable metadata on file system structure and contents
- bulk_extractor: A program that extracts information—including Personally Identifying Information—from disk images without parsing the file-system. bulk_extractor generates reports on the information in both human and machine readable formats, and includes a GUI front-end, Bulk Extractor Viewer.
- sdhash 2.x – A tool to evaluate file similarity using similarity digests.
- Ghex: An open source hex editor that allows users to view a file’s bitstream in hexadecimal format.
In addition, the BitCurator team is in the process of building Python-based reporting tools that reprocess and provide visualizations based on the output of forensics tools that produce Digital Forensics XML; these tools are currently distributed separately via GitHub, and are being integrated into the environment as the project progresses.
The relevance of these tools for humanities research comes into focus when we consider that disk images are fast becoming indispensable units of analysis for scholars seeking to understand the primary sources of digital cultural heritage. A disk image is a bit-accurate copy of the raw media to obtain what amounts to a binary facsimile (or “snapshot”) of every signal or inscription recorded on an original piece of source media. As such, it is the gold standard in both the legal forensics community (where investigators routinely conduct their analysis on an authenticated disk image as opposed to the original storage device) and in archival processing (Woods, Lee, & Garfinkel, 2011). Because disk images preserve a record of both file-level metadata as well as the actual physical traces of data recorded on the surface of the media, they are essential for reconstructing the “original order” of digital records, i.e. correct chronologies of file creation and manipulation (which can be obtained through techniques ranging from file system analysis to digital stratigraphy) (Xie, 2011; Woods and Lee, 2012). A disk image also allows an investigator or researcher access to unallocated or even potentially damaged portions of the original media, creating the possibility of restoring fragments of files that would be unrecoverable after normal copy processes (Kirschenbaum et al., 2009). Finally, a disk image can be used as the basis of an emulated experience allowing a researcher to recreate most aspects of the original operating system and computing environment. All of these activities have clear parallels in traditional textual studies and bibliography. Specialists in those areas routinely seek to understand and describe the relationships among sets of primary source documents, identify and enumerate the distinguishing features of individual documents and texts (using those findings to facilitate inquiries ranging from paleography to constructing version histories), and editing or curating primary source materials for presentation in a variety of formats and settings. A disk image thus manifests a strong analogy to the primacy of material/documentary evidence in more traditional forms of bibliographic analysis, enabling a researcher to analyze numerous aspects of a born-digital object relevant to scholarly concerns. As such, we predict that disk images will become increasingly familiar to scholars and researchers working on late twentieth- and twenty-first century history, culture, literature, and the arts, as more and more leading figures consign electronic records to archives who are processing them in environments like BitCurator (AIMS).
While BitCurator’s primary user community consists of librarians and archivists engaged in the processing of digital materials in a variety of institutional settings, its functionality is also useful to those digital humanities scholars with direct access to born-digital materials (Carroll, 2011; Schuessler, 2012). Digital humanities thus has an opportunity to develop a robust research agenda in conjunction with the digital archives community that would ensure that scholarship in areas like contemporary literature, recent world history, digital culture, politics and government, and the arts proceeds on a sound technological footing, using tools and best practices designed to ensure the stability and reliability (and accessibility) of the born-digital cultural record. While the digital archives and forensics communities have developed mature tools around file system metadata and the extraction of personal identifying information, for example, they lack the digital humanities community’s experience in analyzing complex text corpora. Data extracted from disk images can be redirected to tools and assets ranging from geo-spatial visualization to topics modeling and other forms of textual analytics. The open and extensible nature of the BitCurator environment affords the potential for such collaborations, and so the paper concludes with some use case scenarios in this regard.
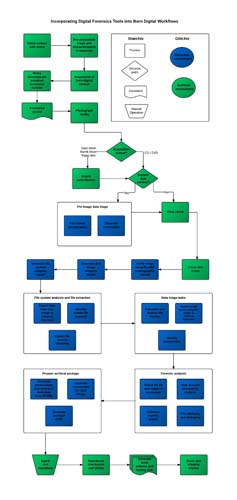
Figure 1. A model BitCurator-supported workflow.