Digitizing Serialized Fiction
July 17, 2013, 08:30 | Short Paper, Embassy Regents F
Introduction
One barrier to locating serialized fiction in a digital newspaper archive is the fact that the serialized fiction themselves are not indexed, and individual articles do not have subject terms or tags associated with them that would identify them as fiction. As a result, articles are difficult to find unless the reader browses a large volume of issues or simply hits upon a salutary keyword search. Keyword searching of the collection is more effective for articles on topics in farming or farm life than for works of fiction. Unless the reader is looking for stories by a specific author or for a known story title, keyword searching of fiction is highly ineffective.
While the software used by most archives does a good job of connecting articles in a single issue, the reader does not know where to find the next installment in a serialized work of fiction, so he or she has to find it manually by browsing the collection or doing a keyword search. Finally, while the OCR scanning was done to the highest standard, this is an imperfect process, and much of the content cannot be adequately OCR’d due to background noise and broken letters, features of the original newspapers that impede scanning.
This paper summarized the process of our project that was completed over 15 weeks in the summer of 2012. Our goal was to complete the manual indexing process that had already been started previously, display serialized fiction articles in a new repository, evaluate multiple software packages to see which ones were the most promising for use in the future, and evaluate any automated ways of finding serialized fiction.
Method and Results
Manual Indexing
We experimented with three digital library systems, a Drupal/Fedora based repository (Islandora) (http://islandora.ca/), converting the fiction into TEI P5 and displaying it in the California Digital Library’s eXtensible Text Framework (XTF) (http://www.cdlib.org/services/publishing/tools/xtf/) and Omeka (http://omeka.org) a PHP-based publishing platform for digital library objects. We were unable to get Islandora’s OCR correction module installed so we stopped using it in favor of Omeka. We used XSLT to transform the PrXML into very simple TEI5 files, which we were able to upload to XTF, but the lack of an editor and the intensely manual process of text encoding was also rejected in favor of Omeka. TEI Example: http://uller.grainger.uiuc.edu:8080/xtf/search
Ultimately, we decided on using Omeka with the Scripto Plugin for correction. Serialized fiction articles in one title, the Farmer’s Wife, was manually indexed in a spreadsheet, and graduate assistants converted those stories from PrXML into an exhibit, added Dublin Core metadata and links to the newspaper archive from the new serialized fiction collection. The end result was index of serialized fiction that would increase the accessibility of these articles. Omeka Exhibit: http://uller.grainger.illinois.edu/omeka/
Crowdsourcing OCR correction
The University of Illinois Digital Newspaper collections are in Olive Software ActivePaper Archive, which has a method for administrators to correct text but not users. Omeka provides a plugin called ‘Scripto’ for text correction that we were able to successfully use to correct the text in selected articles. We also evaluated Veridian (http://www.dlconsulting.com/veridian/), which is a commercial digital newspaper library solution used by Trove Digitised Newspapers (National Library of Australia), From the Page (http://beta.fromthepage.com/) and Islandora (http://www.islandlives.ca/). From the Page and Islandora were both very difficult to install and administer, and while not free we felt Veridian was a much better approach and we are evaluating it as part of our future newspaper digitization efforts.
Text Analysis
How can we identify serialized fiction without having to have a human find it, index it in a spreadsheet and manually extract it from the archive? Certain n-grams are common within serialized fiction such as ‘chapter’, ‘the end’, ‘to be continued’ and could be used to simply search for keywords within documents; we could also calculate which words occur most frequently in fiction vs. other types of articles and use those terms to automatically tag articles.
We also evaluated using topic analysis to find fiction. We evaluated the 580 articles we had already identified as serialized fiction using Mallet to find 25 topics with 25 words each. Figure 1. shows the top 25 topics modeled as a network using Gephi, while figure 2 shows the topic words ordered by frequency.
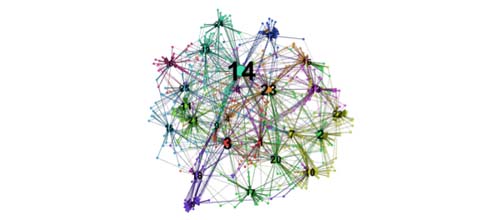
Figure 1

Figure 2
Nodes were ranked by betweenness centrality and topic 14 had the highest at 51,321.01 and its component n-grams along with the other top topics could be used to find serialized fiction in other titles.
One final text analysis technique that could be useful is identifying proper names is Named Entity Extraction. While we made an effort to manually remove names from the topic analysis, as you can see they kept reappearing in the results. By using named entity extraction we could eliminate proper names from the topic analysis to make them more accurate, and to link fiction together by the character’s names. All three of these techniques (keyword frequency, topic analysis, named entity extraction) I plan on evaluating in a future study.
Conclusion
Serialized fiction is an important component of historical newspapers and by making it more accessible to patrons and researchers we can expand the use and usefulness of our digital newspaper collections. The manual indexing approach was relatively inexpensive to accomplish but was time consuming and difficult to do over a large corpus of pages. Two promising approaches to find and digitize serialized fiction in our newspaper archive are adding a crowdsourcing feature to enable users to identify article types and correct mistakes, and utilizing text analysis techniques to identify fiction programmatically. We hope to report on our efforts at the latter at the DH 2013 conference.