Markup Beyond XML
July 19, 2013, 08:30 | Long Paper, Embassy Regents C
Markup Beyond XML
A review of the limitations of XML is not necessary here, as they have been debated as long as XML, and SGML before it, have been applied to data in the humanities. (For example, see Barnard et al. 1988, Huitfeldt 1994, Barnard et al. 1995.) Nor is it necessarily helpful, inasmuch as dwelling on the difficulties (while ignoring the considerable strengths) of XML is not in itself a constructive activity.
However, even when conceptualizing a markup technology that does not face these particular limitations, we can also learn from XML's strengths. In particular, from the concept of generic and “descriptive” markup (Coombs 1987) we have learned that document markup need not be strongly bound to application semantics, but can be declarative and oriented to the information and problem domain (rather than the particular platform and toolset in use), providing many advantages both for modeling and for long-term application independence. Similarly, XML's fairly clean separation of syntax (the text-based format that constitutes XML formally — angle brackets delimiting markup and distinguishing it from text content) from model (most commonly, but not necessarily, the W3C DOM or the related “tree”-shaped model of a document described by the Xpath/XSLT/XQuery family of specifications) has enabled the development of powerful standards-based tools — for both creating and maintaining XML syntax and for processing it — and helped ensure the platform independence and portability of XML technologies.
LMNL, the Layered Markup and Annotation Language, borrows both of these fundamental concepts. LMNL was first described by Jeni Tennison and myself in 2002 (Tennison and Piez 2002). However, its model differs significantly from XML's in two important respects:
I. Where XML stipulates a complete organization of a data set into discrete containers (elements), LMNL simply identifies ranges over a text. Ranges, as sequences of characters (or more formally, of atoms) may overlap with other ranges. In LMNL syntax, this is legal: [poem}Et [red}l'unique [gold}cordeau{red] des [green}trompettes{gold] marines{green]{poem]
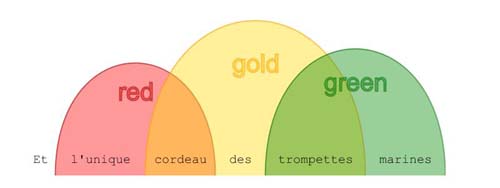
Figure 1.
As identified (in the syntax) by start-tag/end-tag pairs, any range may overlap with any other. Indeed, any relations between ranges — whether one may or does “contain” or “overlap” another — are not conditioned by the rules of LMNL, but provided, when needed, by an application in process. (So an application may say “colors must not overlap”, or “red must not overlap with gold”, but LMNL itself does not.) Thus LMNL markup is like a set of crayons or markers (for marking a text) as opposed to a pair of scissors (for segmenting it).
II. LMNL ranges may be annotated, in a way similar to attributes assigned to elements in XML, but also with significant differences. While in XML, attributes are provided as name-value pairs, any LMNL annotation may have structure: [poem [author}Guillaume [surn}Apollinaire{surn]{author]}Et l'unique cordeau des trompettes marines{poem] Here, the author annotation has content that is marked up: Guilliaume [surn}Apollinaire{surn]. Moreover, in LMNL, annotations may have annotations (as if XML attributes could have attributes), and indeed annotations may encapsulate, comprehend or subsume entire documents (perhaps stored out of line, elsewhere on the network).
Draft specifications for the LMNL model and proposed syntax are at http://www.lmnl-markup.org.
The examples here use markup syntax, but the LMNL model by definition (and in this respect like the W3C XDM) requires no particular serialization format or no serialization at all. The LMNL model is defined in such a way that it can be represented using any capable syntax, or modeled directly in a database or object structure. XML may also be used, and indeed any of the documented XML-based approaches to representing overlap (including so-called milestone elements, or via segmentation and alignment, or using standoff; see TEI P5, chapter 20) may be mapped, usually straightforwardly, into the LMNL model. A simple transformation can rewrite any XML document as a LMNL document; by supplementing this with specialized logic for recognizing any XML-based conventions for representing overlap and expressing them directly as LMNL ranges, any XML that currently represents overlap can be rewritten automatically into LMNL and processed in a LMNL processor. (It is also possible to go back the other way.)
The LMNL model itself is fairly simple. A LMNL instance is defined as a text layer (a sequence of characters) with a set of ranges over the text. A text layer is a sequence of atoms: an atom can be represented using markup, but more commonly Unicode characters (each of which indicates a distince atom) are used. As noted, ranges have annotations. Annotations can be anything, from nothing at all (both ranges and annotations can be anonymous in LMNL) to just a name, to entire documents: annotations have their own text layers, so they can marked up. Annotations, like ranges, may be annotated. And their annotations may be marked up (its content marked with ranges), its ranges annotated, etc. While annotations belong to ranges (or annotations), and ranges belong to text layers (in the documents or annotations over which they range), ranges have no necessary relations to one another except as specified in the application. This means that ranges may overlap even other ranges assigned the same (type) name — so single defined sets of tags may be used to indicate ranges in the text for indexing or annotation, even if these ranges sometimes (or often) overlap. Ranges may also be filtered or associated in ways that represent multiple concurrent hierarchies (not single hierarchies alone, one at a time).
Luminescent, in combination with XSLT stylesheets developed to transform its (XML-based) output, is currently capable of all the following:
- 1. Automatically check for LMNL syntax well-formedness, outside an application.
- 2. Extract XML dynamically from documents marked with LMNL, given a list of elements to represent as (in) the XML tree.
- 3. Analyze the content for overlapping ranges.
- 4. Generate formatted output.
- 5. Generate alternative renditions and visualizations (e.g. SVG), showing structures of relations (and/or the lack thereof) in the marked up text.
- 6. Filter and transform.
These experiments demonstrate the potential of a model supporting overlap for the study of narrative structure (in which narrative and dialogic structures commonly overlap with the native structures of verse, prose or drama) and for prosody (in which verse structure and sentence structure overlap in interesting ways). In addition, many other uses for LMNL can be readily envisioned, whether for supporting indexing, arbitrary annotation, data retrieval and filtering across arbitrary semantic boundaries, or others.
Finally, it must be noted that in a model that supports both overlapping structures and structured annotations, there are expressive opportunities for the representation of phenomena in literary texts (and any complex text) that are unavailable in XML. Consequently, it is suggestive of other models of text altogether — which can be more easily optimized, in many cases, for certain kinds of processing that are difficult, at best, in XML.
Source code for Luminescent is maintained here on github: https://github.com/wendellpiez/Luminescent
At DH2013 I will be demonstrating the pipeline; describing its design, operations, methods and capabilities; remarking on issues and work remaining to be done; and answering questions.
Some LMNL source code
In an application (in which this document is parsed and transformed into an SVG representation), a graphical view shows how cleanly nested the sentence/phrase structure is with the verse structure of this sonnet. The only case of overlap is at the end of line 9 (at the start of the sestet), where it enjambs with line 10 after the only mid-line caesura in the poem:

Figure 2: