The Full-Spectrum Text-Analysis Spreadsheet
July 17, 2013, 08:30 | Short Paper, Embassy Regents F
The most frequent function words have received the lion’s share of attention in authorship attribution and computational stylistics, partly because they seem intuitively unlikely to be manipulated consciously by authors, and partly because analyses based on them have been quite successful. Rare words have sometimes also been studied (Baayen, H., van Halteren, H., and Tweedie. F. 1996; Holmes 1998). Burrows has recently introduced Iota, which focuses on relatively rare words, and Zeta, which focuses on words that are neither among the very most frequent words nor rare (Burrows 2007; Hoover 2007b; Hoover forthcoming; Craig and Kinney 2009). Other researchers have analyzed very large numbers of the most frequent words (Rybicki, J. and M. Eder 2011; Hoover 2007a). And Rudman has argued that “An individual's style is made up of hundreds and hundreds of markers. The more of these that can be shown to be used consistently (within the same genre and time constraints) by the author, the more that can be used in the study” (1998: 153). However, I know of no computational stylistics tool that analyzes the entire word frequency spectrum.
My Full-Spectrum Text-Analysis spreadsheet, designed to do just that, is a Microsoft Excel spreadsheet with macros, using a simple but powerful method of measuring differences between two groups of texts. It begins with sets of texts by two authors, divided into equal-sized segments, and then compares how many segments for each author contain each word, ignoring their frequencies. Any two groups can be compared, but here I describe the simplest comparison, between two authors, Willa Cather and Edith Wharton.
The snippet from the Calculation sub-sheet of the spreadsheet in Fig. 1 clarifies how it is used (shown before the macro has completed the analysis; the buttons are explained below). In cells E7 and E8, the user enters the names of the two authors to be compared (automatically copied into columns A and G and Row 9), then enters the raw word frequencies for the segments into five sub-sheets (see the tabs at the bottom of Fig. 1). The frequencies for the segments that will be used to create the comparison between the two authors are placed in the “Author1” and “Author2” sub-sheets, with the full word list in column A of“Author1” (all segments in this analysis are 2,500 words). Optionally, independent segments by the same authors can be placed in “Author1Ind” and “Author2Ind” and used to confirm that the method correctly attributes texts not involved in creating the initial comparison. Finally, any texts to be tested for authorship are placed in “Test.” (All word frequency lists must be based on the word list in “Author1.”)
The macro, run by clicking the “Analyze & Graph” button, clears out old data, enters formulas, copies data from the sub-sheets into the “Calculation” sheet (columns H and following), shrinks the columns for easier reading. It also copies the word list into column G, and enters their ranks in column F (this is useful for studying where each author’s characteristic words fall in the frequency spectrum). The calculations are performed in columns A-E. Column D records the number of Cather’s segments that contain the word, and column E records the number of Wharton’s segments that do not contain the word. The most frequent words typically occur in all segments and receive a neutral score of 1, but note that her the 6th most frequent, occurs in only 186 of the 193 Cather segments. Column B calculates the percentage of Cather's segments that contain each word; column C calculates the percentage of Wharton’s segments that do not contain each word (both expressed as decimals). Column A sums columns B and C, producing the Distinctiveness Scores (DS). Columns H and following of row 1 show the number of different words (types) in each segment, and below them the percentage of types that are marker words for Cather or Wharton (these figures are not meaningful until the macro has finished). It sorts the words on the DS, with Cather’s most distinctive marker at the top and Wharton’s at the bottom, then selects Wharton’s markers and re-sorts them in reverse order. The sheet can handle 50,000 words, but the full word list for these samples is 30,435 words.
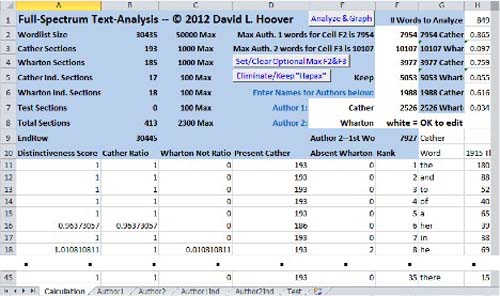
Fig. 1 —
The Full-Spectrum Text-Analysis Spreadsheet, With Data, Macro Not Finished
After the macro has finished, the spreadsheet looks like Fig. 2. Cather’s most distinctive marker, until(row 11), is found in 162 of the 193 Cather segments and is absent from 170 of the 185 Wharton segments. Wharton’s most distinctive marker, continued (row 14,611), is found in just 22 of the 193 Cather segments, but is absent from only 58 of the 185 Wharton segments. (Note that till, a nice authorial contrast to until, is Wharton’s second most distinctive marker.) Rows 2 and 3 of columns H and following show how these markers are distributed in each segment. For example, H2-H3 shows that about 70% of the types in this segment are Cather markers, but only about 33% are Wharton markers. For Wharton’s first segment (not shown), the proportions are roughly reversed: about 66% of the types are Wharton markers and about 37% are Cather markers.
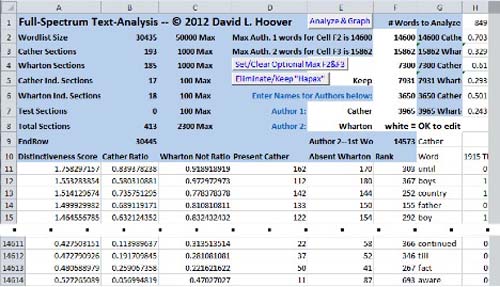
Fig. 2 —
The Full-Spectrum Text-Analysis Spreadsheet, With Cather and Wharton Data
The macro also creates the scatter graph in Fig. 3. The horizontal and vertical axes record the percentage of types in each segment that are Cather and Wharton markers, respectively. Note that all the independent and test segments are correctly attributed. (I have put some texts in “Author1Ind” and “Author2Ind” and some in “Test” for illustration and have deleted some labels to make the graph easier to read.) Although full-spectrum analysis produces excellent results for these authors and texts, more work will be needed to evaluate its general effectiveness fairly.
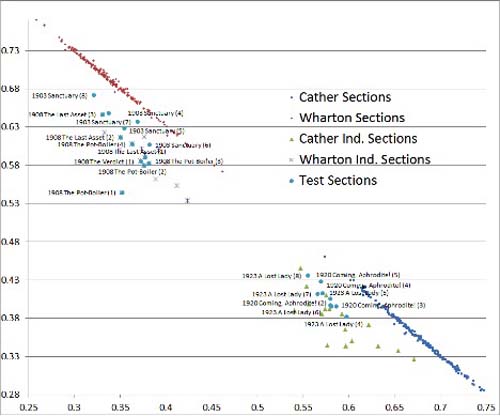
Fig. 3 —
A Full-Spectrum Text-Analysis Scatter Graph, With Cather and Wharton Data
The spreadsheet is designed to facilitate further study. I have included a button that toggles the elimination of hapax legomena. Setting this option to “Eliminate” before clicking the “Analyze & Graph” button removes these words from the analysis. The default range of analysis is full-spectrum, but the “Set/Clear Optional Max F2&F3” button toggles a limit of 500 marker words for each author, for comparison with Craig Zeta, which it then mimics. Half the maximum markers for each author are calculated in cells F4 and F5 and one fourth in F6 and F7, and three sets of results based on these three pairs of numbers appear rows 2-7 of column H and following. If these or any other numbers are pasted into cells F2 and F3, the graph automatically updates, facilitating a comparison between full-spectrum and more limited analyses.
I conclude with two more graphs, Fig. 4 showing the same analysis as Fig. 3, but without the hapax legomena, and Fig. 5 showing line graphs of the same information in Fig. 3 and Fig. 4 along with information based on the 500 most distinctive Craig Zeta markers for comparison (the sheet pastes the data on which these graphs are based to the right of the word frequency information, ready for graphing). These line graphs show less information about how various segments compare, but give a clearer picture of how many Cather and Wharton markers appear in each segment.
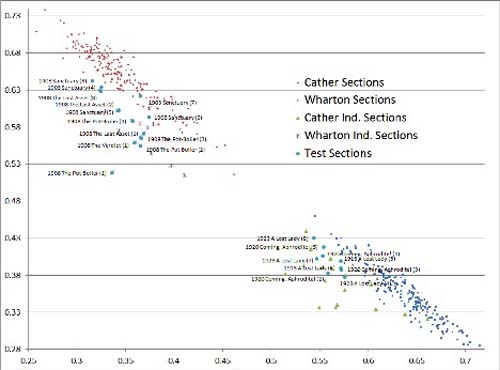
Fig. 4 —
A Full-Spectrum Text-Analysis Scatter Graph, With Cather and Wharton Data
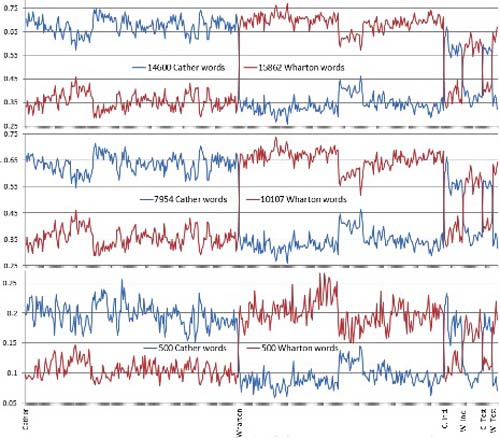
Fig. 5 —
Cather vs Wharton: Full-Spectrum, Full-Spectrum Less Hapax, 500 Markers Each