eResearch Tools to Support the Collaborative Authoring and Management of Electronic Scholarly Editions
July 19, 2013, 13:30 | Long Paper, Burnett 115
1. Introduction
The Australian Electronic Scholarly Editing project is a collaboration between the University of Queensland, University of NSW, Curtin University, University of Sydney, Queensland University of Technology, Loyola University, Chicago and the University of Saskatchewan. The aim of the project is to develop a set of interoperable services to support the production of electronic scholarly editions by distributed collaborators in a Web 2.0 environment.
One of the fundamental challenges faced by the AustESE project is the development of an interoperable data model. In recent years, research focussed on the production and use of electronic scholarly editions has increasingly involved the development and employment of ontologies (Robinson and Meschini 2010; Romanello et al. 2009). The Text Encoding Initiative has provided the necessary elements to describe the textual and material character of documents, but TEI has addressed neither the naming of components of an edition nor the relationships between these components (Robinson & Meschini 2010). Such frameworks are necessary to support the interoperability of the electronic edition and to facilitate and coordinate greater levels of user engagement with annotations.
One of the most significant contributions that ontologies can make to electronic scholarly editions is to more precisely model and capture the dynamic nature of the ‘work’. This provides a more stable framework onto which metadata and annotations can be accurately attached, and also facilitates the efficient execution of workflows that support scholarly editing practices. The importance of acknowledging the complexity and the contingency of the work has been made clear in recent years (Shillingsburg 1997, Eggert 2009). In order to logically integrate the elements of a work into a knowledge-site (Shillingsburg 2006) or a work-site (Eggert 2005), and, at the same time, protect the integrity of transcriptions and images, our approach enables the augmentation of images and transcriptions with stand-off mark-up in the form of annotations. Such an approach contributes not only to theories of scholarly textual editing, but also to theories of knowledge representation in computation (Clement 2011). In this paper we describe the project’s overall objectives and the ontology that we are using to underpin the AustESE Workbench, and we will discuss the practical and theoretical implications of the delivery of an integrated workbench that promises to re-invigorate scholarly editing in Australia.
2. Project Objectives and Ontology
The specific objectives of the AustESE project are to provide the Australian scholarly editing community with an online integrated Workbench that provides:
- collation tools for automatically detecting, identifying and highlighting variations between different versions of a work and that allow the relationship between texts to be visualized, authored or edited
- annotation tools that:
- enable scholars to create and reply to scholarly commentary attached to texts, variants and images;
- capture the annotations as stand-off markup that is discoverable, shareable, and re-usable;
- provide search, browse and visualisation interfaces for annotations;
- enable both manual and automated migration of annotations between transcriptions and facsimiles.
- a workflow engine that captures the sequence of tasks and decision-making steps as well as the provenance of generating an electronic scholarly edition;
- publishing tools that automatically compile electronic scholarly editions into standard publication formats;
- and a repository that supports the discovery, search, retrieval, exploration and re-use of texts and electronic editions.
AustESE Workbench
The AustESE workbench coordinates the scholarly editing workflow and provides access to online tools that support scholarly editing tasks. For the AustESE project, we have adopted a Service-Oriented Architecture, illustrated in Figure 1, with the aim of developing modular, reusable, and potentially distributed components that can be assembled and substituted according to the requirements of each scholarly edition project. To implement this architecture, we are extending existing scholarly editing tools with REST APIs to enable their integration with our content repository and workflow engine, and implementing new open source software to bridge the gaps between existing tools.
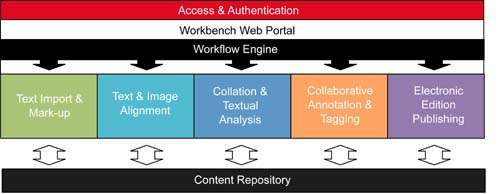
FIGURE 1:
AUSTESE TECHNICAL ARCHITECTURE
Ontologies
The AustESE ontology includes key classes Work, Version, Artefact, Agent and Event, and provides the data model used to organise the metadata and conceptual entities represented within the repository. The AustESE ontology can be mapped onto the IFLA FRBR to link with entities from related databases such as AustLit: The Australian Literature Resource, however it provides additional concepts to those defined by FRBR, to make it easier to model and analyse manuscript materials and fine-grained differences at the level of ‘impressions’ and ‘states’.
The Open Annotation W3C Community Group provides a common data model (Sanderson, Ciccarese & Van de Sompel, 2012) for representing annotations across tools, architectures and collections. The model, which is expressed as an OWL ontology, is intended to be extensible, so that it can be refined to meet the annotation requirements of specific communities. To support the production of apparatus and commentary within electronic editions, we build on the OA core data model with specialised annotation Motivations, as illustrated in Figure 2. We categorise annotations as ExplanatoryNotes, providing commentary or TextualNotes, which provide support for editorial decisions. VariationAnnotations are a type of TextualNote that describe textual variation between versions of a work. These annotation Motivations can be used in search queries and for filtering and sorting annotations to enable selective display and inclusion for print or electronic publication.
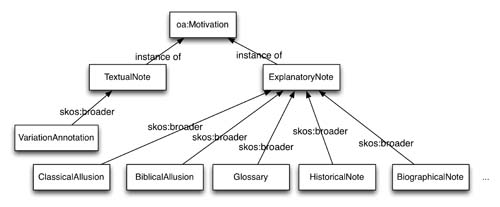
Figure 2:
AustESE Open Annotation Motivation subclasses
We have defined additional properties that may be used within the body of a VariationAnnotation, (as shown in the example in Figure 3), to record metadata about the agent, date or cause of the variation as well as documentary evidence including links to manuscript facsimiles. Within our RDF-based annotation tool and annotation repository, we have adopted a Linked Data approach of using HTTP URIs to identify entities that may be referenced within annotations, including Agents (people or organisations) and conceptual entities (Works, Versions, Artefacts, Events). We use FOAF and Dublin Core to record annotation provenance, and we apply properties from the AustESE ontology to relate the transcriptions and corresponding facsimile images that are being annotated.
Such a conceptual framework necessarily directs attention to the material artefacts it aims to describe, ‘making the archives talk’ through the arguments of editors and readers (West 2011). A ‘virtual archive’ of artefact images provides a foundation upon which transcription and commentary can be overlaid, satisfying the archival impulse of scholarship, and providing a space for multiple, and, perhaps, competing views about how works could and should be represented (Shillingsburg 2010). With the Workbench, the AustESE project aims to facilitate such processes and to support collaborative editorial models that contribute to the development of social editions (Siemens et al 2012).
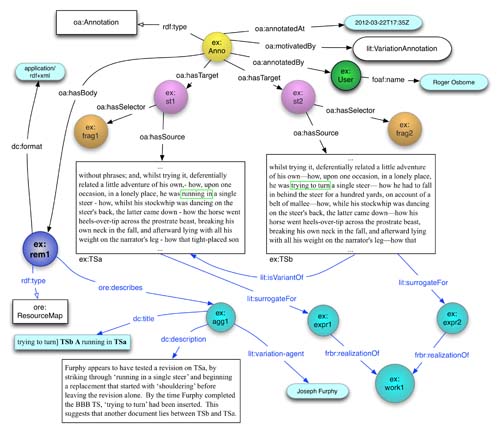
Figure 3:
Annotating Textual Variation
3. Practical and Theoretical Implications
The development of the AustESE Workbench has been informed by several case-studies, particularly the requirements of Paul Eggert’s Charles Harpur Critical Archive and Roger Osborne’s electronic edition of Joseph Furphy’s Such is Life. The complex textual and material situations faced by these projects require the type of infrastructure provided by the AustESE Workbench in order to efficiently store, describe, organise and analyse large numbers of image files and their related transcriptions. Projects such as these can still argue for a particular editorial rationale and contribute new, critically established texts to the system. But with the facility to support solitary and collaborative interpretation in the form of annotations across the archive, the editor’s version can be critiqued or ignored if readers object to the editorial approach. Hans Walter Gabler has recently described the emerging phase of electronic scholarly editions as a ‘paradigm of a relational interplay of discourses, dynamically correlated both among themselves and with an edition’s readers and users: that is, to a paradigm once again of text and ongoing commentary.’ (Gabler 2010) While granting due attention to the integrity of the images and transcriptions within the archive, such a paradigm lends itself to the compilation of ‘revision narratives’ (Bryant 2002) and general commentary that will help to reinvigorate and sustain research on literary works into the future. The AustESE Workbench will achieve this by drawing on Web 2.0 technologies and the Semantic Web to support collaborative social editions and/or finely argued editions produced by solitary editors.
Acknowledgements
The University of Queensland is proud to be in partnership with the National eResearch Collaboration Tools and Resources (NeCTAR) project to create a unique opportunity to develop eResearch Tools that support the Collaborative Authoring and Management of Electronic Scholarly Editions.