Beyond the Document: Transcribing the Text of the Document and the Variant States of the Text
July 18, 2013, 10:30 | Long Paper, Burnett 115
The transcription of primary textual sources is at the center of digital editing projects. The capacity offered by the digital medium allows for the inclusion of much more detailed transcriptions than is possible within the frame of printed editions. But this capacity tempted scholars into attempts to capture every possible aspect of the document in their transcription. Unless we are very careful about the choices that we make in relation to the transcription of a document, we risk making an enormous effort and spending a great deal of money on transcriptions that end up not being very useful. This paper describes our use of an encoding system that allows scholars to present a transcription of the text of the document alongside the variant states of the text, making it possible to go beyond the encoding of documents.
Some important projects in digital humanities are focused on the transcription of documents. Notable examples of this are Transcribe Bentham (http://www.ucl.ac.uk/transcribe-bentham/), the Jane Austen’s Fiction Manuscripts Digital Edition (http://www.janeausten.ac.uk) or Nietzsche Source (http://www.nietzschesource.org/). Moreover, editors such as Hans Walter Gabler who have made the transition from print to digital and who advocate critical editions are shifting their focus towards the transcription of primary sources. For example, Gabler, in his article “The Primacy of the Document in Editing,” asserts that:
…the text should be seen fundamentally as a function of the document. For, after all,… it is documents that we have, and documents only. In all transmission and all editing, text are (and, if properly recognized, always have been) constructs from documents. (Gabler 199)
This re-definition of text as construct from a document develops in Gabler’s argument to become “…a set of document functions comprehensively deriving from the continuous manuscript posited…” (207). This represents a shift from what has been considered the traditional role of the editor as the scholar that establishes the text. Indeed, Peter Robinson points out that:
[Gabler] proposes a complete refocusing [sic] of editorial perspective: away from a concentration on the finished product, the editorial text which is supported by reference to various documents, towards a concentration on the documents themselves, from which an editorial text may (or may not) emerge. This is an immense shift. Gabler proposes that the intense editorial effort which for centuries has seen as its goal the construction of an editorial text, should now focus on the construction of the text of the documents. (Robinson 5)
Robinson’s interpretation of Gabler’s text is informed by my own concept of the text of the document, as developed for the article “The Commedia Project Encoding System.” While working on the electronic edition of the Divine Comedy, I developed a complex encoding system to represent, within a single file, the text of the document and the variant states of the text. In this article, I explain that:
I use the phrase the ‘text of the document’ to refer to the sequence of marks present in the document, independently of whether these represent a complete, meaningful text. That is: the reader sees a sequence of letters, occurring in various places in relation to each other (perhaps between the lines or within the margins) and carrying various markings (perhaps underdottings or strikethroughs). These make up what I here refer to as the text of the document. (Bordalejo 2010).
I am not the first in referring to text of the document, G. Thomas Tanselle has contrasted the text of the document (1978; 1996) with “the text of the work” (Tanselle, 1996).
The text of the document, then, can be recorded as a sequence of meaningful marks present on a particular document. MS. Riccardianna 1005, a witness of Dante’s Divine Comedy, presents the following example:

This could ordinarily be represented by: <del>dura</del><add>duro</add>
In our transcriptions, however, we represent this as: <app> <rdg type="orig">dura</rdg> <rdg type="c1">duro</rdg> <rdg type="lit"> dur<hi rend="ud">a</hi>o</rdg> </app>
Here, the last reading, <rdg type="lit">, represents the text of the document literally. Unlike traditional TEI recommended encoding we do not use <add> or <del>, on the premise that both of these confound a statement of editorial interpretation (this is a deletion or an addition, so we should read the text with or without these characters) with a statement of what appears on the document (there is a mark under these characters; they are placed interlineally). In our view, the statement of what we see on the page is a different order of declaration from a statement of how we think this should be read. The aim of <rdg type="lit"> is to present the meaningful marks we see on the document. The statement of how we think these marks should be read, as a sequence of readings, should be left for the other elements within <app>: thus, <rdg type="orig"> and <rdg type="c1">, representing the different perceived stages a particular text has gone through during a process of revision, from its original (“orig”) to first corrected state (“c1”). All these statements — <rdg type="lit">, <rdg type="orig"> and <rdg type="c1"> — are interpretive. However, they are interpretive in different ways and serve different purposes.
The TEI, in “An Encoding Model for Genetic Editions” (http://users.ox.ac.uk/~lou/wip/geneticTEI.doc.html#index.xml-body.1_div.1_div.1) includes some similar elements to the ones developed for our edition of the Commedia. Consider this example from “An Encoding Model for Genetic Editions”:
“The following example, taken from a manuscript of Jane Austen's Sanditon, shows a rewriting where a pencilled passage has been fixed with ink, with some modification:
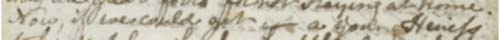
Image from page 70 of the Sanditon manuscript
In this example, Austen sees in the fixation an opportunity to manipulate the text previously written, and thus changes the pencilled could but get to the inked could get. A simple way of encoding this might be as follows: <ge:rewrite cause="fix" hand="ja2" stage="#s1"> Now, if we could get <del stage="0">but</del> a young Heiress</ge:rewrite>”
In our proposed system, not originally designed for genetic encoding but easily adaptable for this purposes, we would encode it as: <app> <rdg type="orig">Now, if we could but get </rdg> <rdg type="c1">Now, if we could get</rdg>> <rdg type="lit"> <seg type="overwritten"> <seg type="orig" rend="pencil">Now, if we could but get </seg> <seg type="c1" rend="ink">Now, if we could get</seg> </seg> </rdg> </app> Both systems explicitly state that there was an original text, written by Jane Austen and that the text was rewritten by herself. The “lit” reading in my proposed transcription specifies that this was originally written in pencil and that the second version of the text was written in ink. In my transcription, it is clearly stated that the original form of the text was “Now if we could but get ” (written in pencil) and that this was altered to “Now if we could get” (written in ink). In contrast, in the proposed TEI encoding it is not at all clear from the use of the various attributes (stages “0” and “#s1”) and from the <ge:rewrite> and <del> elements what was originally written, what it was revised to, and how this was done.
For our purposes, we find that by stating explicitly what occurred to the text, that is whether it was stroke through, underdotted, underlined, erased, scrapped or rewritten, we avoid the ambiguity of the <del> element. The <add> element has also been set aside, to be replaced with markup that indicates position or mode of insertion.
The encoding system being used in our projects is TEI compliant, but it attempts to serve the purposes of various types of scholarly editions. For the purposes of textual scholarship, it is necessary to have a clear idea of what is meant by “representing the text of the document.” In any case, it is not enough to represent the text of the document, we must also represent variant states of the text and give editorial interpretation a more explicit place in the transcription of primary sources.