Semantic Augmentation and Externalization in the Humanities: a Demonstrative Use Case
July 17, 2013, 13:30 | Short Paper, Embassy Regents E
1. Introduction
The Web is rapidly becoming an important source of documents and information for scholars in diverse disciplines and it is opening new scenarios for communication and collaboration. Scholars do not only need to easily find and access open content online, but also to be able to work with it, producing new knowledge and exchanging it with others. By means of content annotation and augmentation, two of the so-called “scholarly primitives” (Unsworth, 2000; Palmer et al., 2009), scholars have been doing this for decades. Their work consists, among other things, in enriching texts (or other kind of intellectual works) with new information, to advance the knowledge of a certain domain. Finally, externalization is an equally important scholarly primitive as it allows presenting results to the community; this usually corresponds to write a paper in the “traditional” academic world.
Effectively translating these primitives in the digital world is the great challenge and opportunity of Digital Humanities. With such purpose, it is commonly accepted that structuring data and metadata about digital objects using standard formats and schemas is a needed step to make content effectively accessible on a global scale. The Semantic Web technologies and Linked Data paradigm have become growingly accepted a way of representing, contextualizing data and making it interoperable(Gradmann, 2010).
The basic idea behind this paper is that the Semantic Web technologies can be used not only to properly represent “static” metadata but also to effectively structure annotations and make their semantics “explicit”. On one side, this allows scholars to create new data and to contribute to the Linked Data Web. On the other, it enhances the externalization of such created knowledge easing the creation of rich and innovative data visualization applications. This enables a “virtuous circle” in which the knowledge generated by scholars can be merged with other data and become the learning and researching object for other scholars.
This paper presents an experimental scenario showing how annotation, augmentation and externalization of knowledge can be performed with (Semantic) Web tools that are currently under development and evaluation in the SEMLIB [1] and the DM2E [2] EU projects.
After having shortly introduced Pundit (Morbidoni et al., 2011), we present a demonstrative prototype, based on Edgemaps (Dörk, Carpendale and Williamson 2011), where structured annotations are reused in a Web application to visualize a graph of influences among philosophers.
2. Pundit and Semantic Augmentation
Pundit is a semantic annotation tool that allows building structured data about digital objects, annotating entire Web pages down to single paragraphs, sentences or words. Web contents can be semantically augmented, establishing typed relations among different kinds of “entities”, and contextualized, linking them to the Web of Data. For example, a scholar can state that a certain text excerpt “cites” another one, that it “describes” the subject of a picture, or that it “refers to” a place or a person.

Figure 1:
Augmenting original content with semantically structured annotations
Augmentations always preserve authorship and are represented in RDF using Named Graphs. Augmentations, even when made by different users, can be merged to form a semantic graph, as the one shown in Fig. 1, where text fragments are connected with images, vocabularies entries and Linked Data sources as Freebase. Note that, as Freebase is an RDF data source itself, links from an annotation to a Freebase entity can be used by machines as possible gateways towards the Web of Data, where they can collect additional information (e.g. Kant date and place of birth)and further augment the original knowledge.
Nowadays, while some of the basic activities scholars do, as reading and writing papers, are already well supported in the digital world, some essential scholarly primitives, such as annotation, augmentation and externalization, do not yet have a clear support in terms of appropriate software tools.

Figure 2:
Pundit in action
- Augmentation of online content:Pundit provides different GUIs allowing the annotation of several media contents at different level of granularity and complexity, ranging from simple comments and semantic tags to triples(statements), where different kinds of “items” as text excerpt, images and fragments on images are connected by semantically defined relations.
- Contextualization, by linking contents parts to the Web of Data (e.g. DBPedia, Freebase)or to controlled custom vocabularies.
- Simple aggregation. It allows collecting (and reusing in annotations) items of interest.
- Collaboration. In Pundit annotations are collected in “notebooks” (each user can have multiple notebooks)that can be kept private or shared with others.
In Fig. 2, a screenshot shows the Pundit GUI. Annotations con be composed as triples of the form “subject-predicate-object” (as shown in Fig. 3). More details about Pundit, as well as a live demo, can be found in (Grassi et al., 2012; Nucci et al., 2012) and on the project Web site [3] .
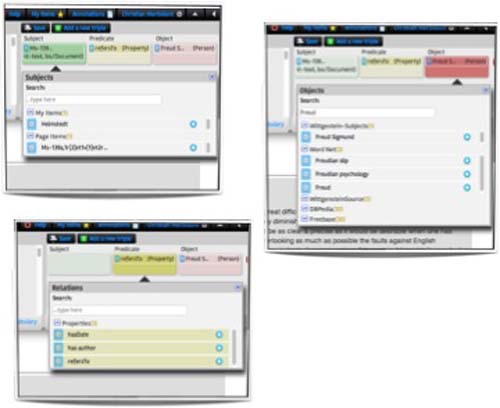
Figure 3:
The Pundit triple composer.
3. Consuming collective knowledge: externalization
In Pundit, semantic augmentations are stored as RDF named graphs and made accessible to software by means of SPARQL endpoints and RESTful HTTP APIs. This allows external applications to easily fetch data and mix it with other Linked Data sources. For example, in the SEMLIB project the collective knowledge created by annotators is reused by a Semantic Recommender System (Policarpio, et al. 2012; Fossati, et al. 2012), which creates similarity links among contents in a digital library, offering an additional navigation layer to users.
3.1 Edgemaps Visualization: A Demonstrative Use Case
Data visualization is not a new topic in the Digital Humanities, as witnessed by projects such as Edgemaps(Dörk, Carpendale and Williamson 2011), where an interactive graph visualization represents philosophers in a timeline or in a similarity graph, showing their influences. The demo shows influence relations coming from Freebase, a well know general-purpose Linked Data repository [4] .
While the visualization is intuitive and has been highly appreciated in the Digital Humanities community, scholars are also concerned with questions like: “Why exactly the graph says that Marx influences Gramsci?”, ”What is the evidence of that in the primary sources?”, “Who said that?”.
The simple idea behind the proposed demonstrative application is to feed the influences graph with precise statements made by scholars, so that each edge in the graph can be linked to an annotation that “justifies” its existence, linking back to primary sources.
In our example, we annotated open contents on Wikisource.org, which publishes in a wiki-form a big amount of primary literature. To do this, Pundit has been customized to accommodate semantic relations extracted from the CiTO ontology [5] . The relation set includes predicates like “cites” and “quotes”, as well as other more specific ones like “discusses”, “cites as sources”, “agrees with”, etc. The Pundit bookmarklet allows loading the Pundit annotation environment on any Web page, and annotating the text while browsing it in its original location (Wikisoruce.org).
Figure 1 shows how Pundit can be used to produce an annotation that connects two texts from different philosophers. The dropdown menu allows specifying a precise relation among the ones proposed (e.g. cites, agrees with, etc.). In terms of RDF triples the annotations would look like the following:
- :text_1 cito:agreesWith :text_2.
- :text_1 dc:creator freebase:John_Locke.
- :text_2 dc:creator freebase:George_Berkeley.

Figure 4:
Creating a semantic annotation, composing a triple(or statement)with Pundit.
Finally, we created a simple Web application based on Edgemaps to load influences relations from users augmentations: each time an annotation exists that connects texts from two different authors a corresponding edge is created in the graph connecting the two authors. When browsing the graph, a scholar can see all the annotations that “establish” a specific influence link with another philosopher selecting an author, as shown in Figure 2. The demonstrative application [6] implements a simple HTTP API with the following parameters:
- nbs, comma separated IDs of notebooks (users personal collections of annotations) to get data from
- source: [freebase|pundit], tells the application if load data from freebase only, from pundit only or from both.

Figure 5:
Showing evidences of philosopher influence with a Timeline Visualization
For example, at the following URL: http://metasound.dibet.univpm.it/thepund.it/edgemaps_demo/demo.html?nbs={c4a2729c}& source={freebase,pundit}#phils;map;;/en/john_locke; the Edgemap shows relations among John Locke and other philosophers retrieved both from freebase data and from a Pundit notebook (whose id is c4a2729c). By mouse over on Berkeley, a box appears showing an annotation that “justifies” the relation. A scholar can easily see who is the author of the annotation, read the annotated text and go to the annotated Web page to see the information in its original context.
4. Conclusions
In this paper, we introduced the concept of semantic augmentation on which Pundit annotation system is founded and presented an example of how semantic data created by scholars or professional con drive live externalizations of a research activity. More experiments are currently undergoing to implement the proposed externalization paradigm also in other scenarios. Another example application has been developed for data journalism, whose detailed description is out of scope here, which allows to put in relations public declarations of politicians (annotated from online newspapers) with the trend of financial indicators [7] .
Acknowledgements
The research leading to these results has received funding from the European Union's Seventh Framework Programme managed by REA-Research Executive Agency [SEMLIB — 262301 — FP7/2007-2013 — FP7/2007-2011 — SME-2010-1]. The research is also supported by the DM2E project, funded by the European Commission's "ICT Policy Support Programme" (ICT PSP), agreement No. 297274.