Digging into Human Rights Violations: phrase mining and trigram visualization
July 17, 2013, 10:30 | Short Paper, Embassy Regents E
I. Introduction
Digging into Human Rights Violations (DHRV) is developing a computational reader for large text archives of human rights abuses so as to discover the stories of hidden victims and unidentified perpetrators only apparent when reading across large numbers of related documents. In part, this project began with an observation drawn from Benetech’s Human Rights Data Analysis Group’s (HRDAG) report on the Bosnian Book of Dead (Ball 2007). In their report on the tabulation of fatalities resulting from ethnic cleansing undertaken by the Milosevic regime, HRDAG was highly concerned with the de-duplication of entries. This over-reporting of individual victims within human rights corpora is endemic, and represents an opportunity for a system that can read across a corpus. For example, in the 511 interviews comprising our test corpus, one named individual appears more than 60 times. How many times might an unnamed individual reoccur? Automated readers exist that classify documents, produce summaries (Nenkova 2011), extract significant information (Strassel 2008) and highlight sentiment on a perentity, sentence, paragraph, or document basis (Pang 2008). This type of analysis works best with well-defined figures, such as occur in newspaper articles or government documents. That partially describes reports of human rights violations, as each report generally describes a victim’s perspective of one limited event. Currently, these systems have difficulty parsing peripheral entities, indeterminate language, or references that go beyond the boundaries of one document and are only significant when traced across documents; many reports peripherally describe the fates of other victims. These implicit, buried links and duplicate reports amongst records enable horizontally reading across records collections, rather than vertical reading through one record.
The technical goal of DHRV is to create an NLP system that facilitates cross-document coreference of entities in collections of witness statements and interviews within the domain of rights. This project’s approach to resolving the task (Kibble and Deemeter 2000) described as “whether or not two mentions of entities refer to the same person,” begins by considering the subtype of anaphora (indicative language within a document) known as exophora (indicative language across more than one document), and relies on placing pronominal entities within a high-order Event Trigraph of location, time, and name. Because temporal information is so often referential and ambiguous, and therefore difficult to extract and correlate (Northwood 2000) our approach uses a phrase-based establishment of semantic context to support identifying the temporal context. This noun- and verb-phrase extraction, collocation detection, and semi-automated matching, feeds a 2D planar visualization similar to network graph models. Uncertainties in the document and information retrieval processes are visualized to allow researchers to confirm whether entity occurrences should be conflated. Because much human rights documentation contains sensitive information that cannot be made public, this project is prototyping with another historically significant corpus that shares many structural features to our primary data: the World Trade Center Task Force Interviews conducted with first responders to the attacks of September 11, 2001.
II. Event Summarization Based on Matching Phrases
Our main stratagem is to situate entities in the series of events that define their appearances. Phrases useful for this process accord to a “journalist template,” of Who, What, When, Where, and Why, and are situated in the events reporting schema developed by Patrick Ball for human rights violations reporting (Chang 2012, Ball 1996). The goal is a system that can automatically extract these important entities as phrases, and based on these extracts, allow for the recognition of duplicate entities across documents. A perceptual diagram of the system is shown in Fig. 1.
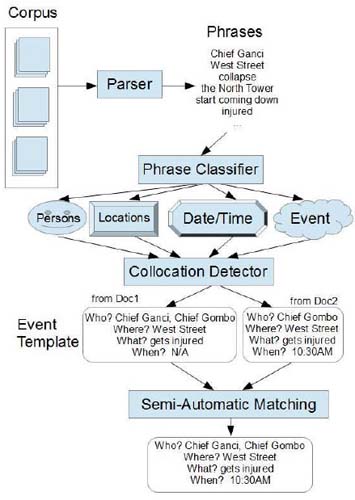
Figure 1:
Phrase mining perceptual diagram
In the system, the noun phrases and verb phrases are first extracted from a parser. Then a phrase classifier is used to determine which phrases fall into important entity categories such as Person names/Geographic Locations/Date/Time or depiction of an event. After classifying these phrases into categories, a module called Collocation detector is ran to detect which of the detected entities are described in the same context within a passage in the corpus. This collocation of phrases is different from the collocation of words usually used in NLP, in that it captures instances of the collocations, instead of a global probability. A collocation is only true when multiple elements correlate. After a set of collocated phrases have been detected, they are placed into the event template and fed to a visualization engine. Human observers then decide which cross-document entities are identical. The engine computes automatic scores to make suggestions to the observers on which events and entities should be merged.
III. Phrase Extraction and Classification
The first step of phrase extraction is done by running a full parser on each document and then extracting all the retrieved noun phrases and verb phrases from the parse tree. We decided against using a shallow parser (chunker) because it has lower recall (may not capture all the desired phrases) than a full parser. The parser we are using is the Stanford parser (Klein 2003(1), Klein 2003(2)). From the extracted phrases, we formulate a classification task for labeling important phrases for event extraction. The important phrases in our research is different from the traditional named entity recognition (NER) problem in NLP, in that we are seeking to connect names to unnamed entities. We have 8 categories for important phrases: Organization, Person, Title, Location, Date, Time, Event, Miscellaneous and the background category of Unimportant. Of these categories, some are traditional NER or TimeML categories. Event and Miscellaneous labels are new, and determine some important phrases that might not be readily interpreted as named entities. Phrases such as “the pedestrian bridge,” “the ferry,” or “the second tower” which are not identifiable as a particular named entity, but might be crucial in depicting the event are classified as Miscellaneous.
To maximally utilize human knowledge in the phrase labeling phase, an unsupervised selection mechanism selects the phrases to be labeled. In this mechanism, phrases are ranked by a score that is similar to a frequency or N-gram model, but discounts the probability of a phrase if it is very common in a background corpus
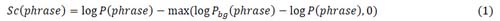
where log P(phrase) is computed by an N-gram language model trained on the current corpus, and log Pbg(phrase) is based on a Ngram language model trained on a background corpus that is supposed to contain documents of all kinds. Under this model, the probability of a phrase is only discounted if Pbg(phrase) > P(phrase). This application of Term Frequency–Inverse Document Frequency (Cohen 2002) helps us to find frequent phrases in the corpus which are not popular in the background corpus. The phrases with top scores are manually labeled. By this approach we can obtain the labels for the most frequent and unique phrases in the corpus, which are likely to be more important in isolating an event. Our N-gram training uses the modified Kneser-Ney smoothing (Chen 1999) from the MitLMpackage (Hsu 2008). The background language model is obtained from Microsoft Web Ngram Services. Given a set of human-labeled phrases, we then train two levels of classifiers on these phrases. At the first level, a binary Important versus Unimportant phrase classifier is trained. At the second level, a one-against-all multi-class classifier is trained for each of the phrase category described above, except Miscellaneous, which serves as the background category for Important phrases. The features used for the classifiers are common NER features (Zhang 2003, Ratinov 2009), plus standard bagof- words features. For the Date and Time phrases, we make use of the SUTime library (Chang 2012) which matches date and time expressions using an extensive set of rules defined by regular expressions. The classification of these Time and Date phrases do not depend on our own human annotation.
IV. Collocation Detection and Event Templates
For the collocation we use a simple metric: a Gaussian kernel on the distance between mentions of different phrases. Formally, the collocation probability of one occurrence of a phrase, given a set of other phrases is defined as:
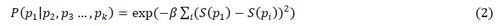
where S(pi) is the sentence number where pi occurred. Given the defined conditionals, one can compute the joint probability P(p1, p2, p3, . . . , pk) and use a threshold to determine which phrase set goes to an event template.
V. Visualizing Unvertainty in Event Trigraphs
Depending upon the context, uncertainty refers to statistical uncertainty, ranged values or missing data (Pang 1997). Uncertainty can be introduced in the data during acquisition, processing or even visualization. In this paper, since the underlying data has been extracted from narratives, which in turn lacks precision, uncertainty is introduced right from the data acquisition phase. These uncertainties include the temporal, “By this time, it had to be 11:00 o'clock at night” and “at that time I noticed,” locative, “I guess that would be North End Avenue,” and entity, “At this point I had my five guys" [WTCTF 9110250]. One of the major goals of this project is to visualize the triadic relationship amongst character, time, and location while incorporating these uncertainties.
In (Skeels 2010), the authors present a survey of the existing works on uncertainty visualization. The survey shows that most research in this area is in the field of geospatial (MacEachren 2005) or scientific visualizations (Lodha 1996, Grigoryan 2004, Wittenbrink1996). It also states, "[t]he main techniques developed include adding glyphs, (Wittenbrink 1996, Lodha 1996) adding geometry, modifying geometry, (Grigoryan 2004) uncertainty in a model to decision makers (Walker 2003) modifying attributes, animation (Lodha 1996, Gershon 1992) and sonification.(LodhaSonic 1996).” To convey the time-location-character data and the associated uncertainty visually, in this paper, we introduce a trigram based visualization called an Event Trigraph.
An Event Trigraph is a 2D planar diagram consisting of events as its building blocks. An event in this case is a 3-tuple consisting of the basic elements derived from the phrase mining method detailed above to yield three elements: time, location and entity. Events are represented visually as triangles with the aforementioned basic elements as vertices connected with weighted edges. The weights represent the confidence value in the relation as obtained via our text mining methods. These confidence values show how likely is the connection both between two elements and amongst the trigram. Figure 2 shows a trigram with confidence values and elements.
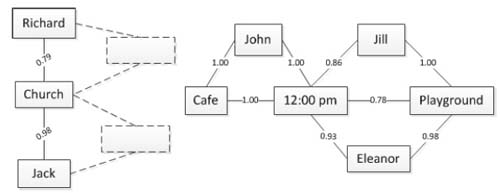
Figure 2.
Event trigraph with uncertainty values and voids
Confidence values peak at 1, or a certain relationship between two elements. To reduce visual clutter due to the excess number of edges and vertices, we employ details on demand (Shneiderman 1996) and filtering capabilities on the dataset. The users can also drag and drop the events over other events and manually enter the confidence values to present the associativity between two or more events. Since the user loads multiple documents at a time, this feature enables users to visually associate events in different documents — the main forte and a unique aspect of our visualization. Furthermore, since the resulting data structure is a weighted network graph, many graph theory algorithms can be readily applied, thus making it scalable.
VI. Conclusion
As reports are processed by this method, the diagram builds in complexity and supplements each individual event trigraph with ones that potentially correlate. In the figure above, John-Café-12:00 pm is correlated to Jill-Playground-12:00pm across the time element, and Jill-Playground-12:00 pm correlates to Eleanor-Playground-12:00 pm across both time and location elements. This aggregated event trigraph builds to represent a corpus, and offers a method for correlating the collocation of entities across documents, and potentially identifying unnamed entities within said corpus.