An Interactive Interface for Text Variant Graph Models
July 18, 2013, 10:30 | Short Paper, Embassy Regents F
In the last three years there has been an increasing adoption of the variant graph as a suitable computer-internal data model for textual variation in tools and applications such as NMerge (Schmidt & Colomb 2009), CollateX (Dekker & Middell 2011), and Stemmaweb (Andrews & Macé 2013). The variant graph model can be visualized easily and succinctly; these visualizations become for the text researcher the first interface through which to approach the particular similarities and differences in a given text. In this short paper we consider from the theoretical perspective some hermeneutic risks inherent in the static visualization most commonly used at present, when the interface stands between the scholar and the data model (whether produced by a collation tool such as CollateX or NMerge, or generated from a published critical apparatus or text collation). The result of our application of the theory is the tool we present, meant to address these risks in part. Implemented in JavaScript [1] , the tool allows the user to interact with and modify the model of a particular text from within the browser window. By doing so the scholar can move beyond the 'black box' nature of visualizations produced by analysis tools and test alternate hypotheses for understanding a text.
Most visualizations of data analysis results are by their nature static, and the variant graph has so far been no exception. A typical example of a variant graph visualization is given in Figure 1, which shows part of a collation result of a line of text obtained from CollateX. (Example adapted from the prologue of the Canterbury Tales (Solopova, 2000; Robinson 2000).):

Figure 1:
Partial collation of a line of text of the Canterbury Tales' prologue.
Each of the manuscript witnesses A, B, and C takes a single path through the possible readings, indicating the version of the text that appears in the witness itself. The variant graph is a compelling and concise means by which we can display the phenomenon of text variation. However, from the given example it is clear that there remains room for further interpretation: should spelling variants such as 'teh' and 'the' always be represented as having equal impact on the text with transpositions such as the one between 'drought' and 'march'? Does the alignment of witness C's 'teh rood' make sense as it stands?
The initial model is thus not entirely satisfactory; there is a clear need for the scholar to express more information or to express the variation more exactly. As long as the graph remains static, our example reflects a general danger inherent to visualizations of digital models of humanities data. An interface is meant to make an internal computer model tractable to a user, but paradoxically it also imposes a barrier: it most literally stands between the user and the model. The user can not change the model; he or she can basically only inspect it insofar as the interface visualizes it. In this sense the interface becomes a display practice enforcing one-way communication (Rijcke & Beaulieu 2011). The extent to which a visualization is interactive and alterable will consequently have an inverse relationship to the impression of finality or correctness that the user will come away with. A high degree of interactivity arguably conveys an impression of interpretability and malleability of the data and results visualized. In contrast, a static visualization produced by a computer tool carries with it an aura of correctness or immutability — even if it is not the only such visualization. If the scholar/user is unable easily to interact dynamically with the model, or even to modify it, then the danger arises that the visualization as posited by the computer analysis will be regarded uncritically and accorded a problematic or even false authority.
Current automated collation practices are a good example of this phenomenon. If an automatic collation algorithm such as that employed by CollateX chooses arbitrarily between two equally good text alignment scenarios, then unless the user is able not only to visualize the results but to manipulate them and explore the equally valid alternative scenarios, the ‘answer’ produced by the computer will tend to be seen as the ‘correct’ collation. Interactivity can thus be seen as an inherent and indispensable part of any sort of modeling of humanities data if the model is to be accepted, refined and used more widely in the field. In the case of variant graphs resulting from computed collation, essential interactions include:
- annotating variants with information about how they are related
- combining multiple words into one reading (e.g. 'what/so/ever') to better express the mutation as it occurred
- splitting words into multiple readings to show more finely-grained variation
- altering or correcting an initial collation
To enable and enhance such interactivity we present a self-contained and generalized JavaScript library for the interaction with and modification of variant graphs produced by online collation services directly in the browser. The library, currently in use by the Greek New Testament Editio Critica Maior project at the Institut für Neutestamentliche Textforschung (INTF)in Münster [2] and the 'Stemmaweb' application of the Tree of Texts project at KU Leuven [3] , can be applied to any research context wherein a variant graph would be appropriate. Users can relate parallel variants, merge or split variant readings, and regularize variants where appropriate to more easily home in on the variants under investigation. Figure 2 shows our variant graph example annotated with different types of relationship.
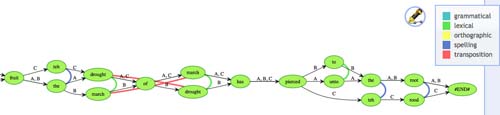
Figure 2:
Partial collation of a line of text of the Canterbury Tales' prologue annotated with various types of relationship.
The scholar may make explicit his or her model of variation by defining the types of relationships that can occur between variants, as well as criteria concerning when these variants can or cannot apply (must the variant readings occur in parallel within the text? must they not occur in parallel, e.g. for transpositions? Does the existence of one relationship imply the existence of another?) These interactions with particular instances of a variant text model allow users to adapt, correct, and extend the results of an automated collation engine, thus making the results produced by the software less fixed and more open to scholarly interpretation. To further support interactivity with the model we experiment with methods of machine recognition of user adjustments in context — for instance, we scan the graph using a vector cosine measure that takes into account the two nodes of a user defined relationship and their existing direct adjacent nodes to identify contexts in the graph that are similar to the context where the user adapts the graph, producing automatic suggestions for where the same relationship might apply under the same conditions elsewhere in the graph.
The clear advantage of enabling interactivity is that the problem of one-way communication between visualization and user is resolved: the variant graph model of a particular text becomes a much more tangible and expressive means to engage with and to conduct research into the text in question.
The interactive engagement with a specific instance of a computer model is a first step in our trajectory to enhance interactivity with current state-of-the-art text collation tools. Future research and development work will focus on feeding instance-based manipulations of collation results back into the reference models of online collation services. As a scholar works with a particular graph, the interactions with that instance of the collation model will be captured by decision trees. These trees can be used by the processes backing the collation model to amend the collation and graph construction, not only for specific instances but also for the general model, thus changing collation engines from rather static rule-based automatons into adaptive algorithms that learn from expert input and feedback.
References
Notes
1. http://en.wikipedia.org/wiki/JavaScript
2. http://egora.uni-muenster.de/intf/aecm/aecm_en.shtml
3. http://treeoftexts.arts.kuleuven.be/