A Comparative Kalendar: Building a Research Tool for Medieval Books of Hours from Distributed Resources
July 17, 2013, 08:30 | Long Paper, Burnett 115
The Book of Hours is perhaps the most ubiquitous type of surviving medieval manuscripts. Each unique book contains a wealth of information about liturgical practices, social and private use of books, manuscript production and decoration, and personal and local choices for the creation of private devotional collections. Each Book of Hours contains a Kalendar that lists feast days for the entire year. These document the standard days for liturgical celebration, but are filled with local and temporal variants that paint a picture of the ways in which practices change according to regional interests over the centuries. Any attempt to curate and control a project devoted to cataloging Kalendar variants in a single team or location suffers from the sheer volume of potential inputs to the project. Further, the standard form of the Kalendar invites widespread contributions from interested scholars and the broader public. This paper describes a comparative Kalendar built from distributed resources served from multiple participating tools and repositories.
This distributed environment relies on repository/tool interactions to share image data in multiple tool environments, and harvest the tool output to build a discovery and viewing environment that can grow as more data is added from any participating tool or repository. These interactions rely on two principle interchange protocols: the SharedCanvas data model, used to aggregate distributed resources; and the International Image Interoperability Framework image API for standardized image resource access.
The SharedCanvas data model (http://www.shared-canvas.org) specifies a mechanism for representing a real-world manuscript object as a collection of two or more blank “canvases” each with a URI and an aspect ratio. Information, including digital image surrogates, is then associated with this canvas using the OpenAnnotation specification. This approach decouples information “about” the real-world object from the digital surrogate that could be used to illustrate that object on the web. Because it is quite possible that a single real-world resource will have multiple digital surrogates all purporting to represent the same thing, this approach makes it possible to build a digital facsimile utilizing a choice of digital surrogates without affecting the other information associated with the object (like transcriptions, scholarly commentary, or other metadata).
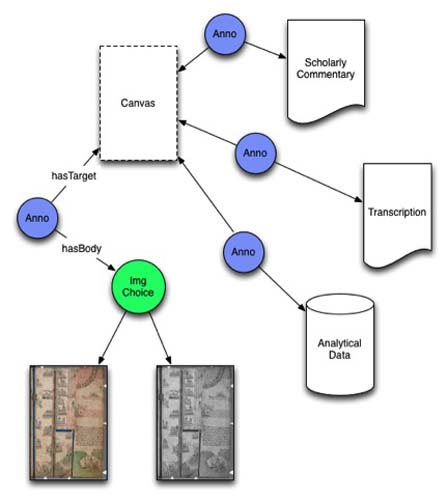
The International Image Interoperability Framework’s image API (http://lib.stanford.edu/iiif) specifies a RESTful web service to deliver a requested image with a number of specified parameters. These include: image format, size, rotation, cropping, and color. The API allows standardized image retrieval from disparate repositories, leading to the ability of tool developers to pull content in an efficient way from any participating host repository. More importantly, this API allows contributors to the Kalendar project to work with from a number of different interfaces and use image data served from a number of different repositories, allowing scholars with a regional or temporal focus to compare books held in different modern repositories.

The participating repositories in this effort are the Stanford University Libraries (serving content from the Walters Art Museum manuscript collection, the Parker Library, Corpus Christi College, Cambridge manuscript collection, and Stanford’s own collection), along with other participants of the Digital Manuscript Technical Council (http://dms.stanford.edu/). This selection of content offers a variety of geographically and chronologically diverse Books of Hours, leading to an initial dataset that highlights both the consistency of some Kalendar elements over three centuries (13th, 14th, and 15th centuries), and the variants that provide insight into localized practices.
The tools used for this project are T-PEN (http://t-pen.org/TPEN) and DM (http://ada.drew.edu/dmproject/), specialized tools for transcription and annotation of medieval manuscript content. A user of either tool has full access to any of the manuscripts served from the participating repositories, and can add transcriptions of Kalendars while also adding structured data to help organize the material for further analysis and display. Both tools produce outputs that link user-generated information about the Kalendars to a region-constraint on the canvas that represents the page of the real-world manuscript. The tools provide a web service for exposing user-generated information that is then aggregated into a discovery and display interface.
This approach reduces the need for any one institution or project to host and serve every image that might be used in the Comparative Kalendar, to provide the user interface tools for transcription, commentary, and analysis, or to control and curate the input and output. The mechanism for user-interaction allows a user in any of the participating tools to choose content from any of the participating repositories. This allows a user to choose the working environment that most suits the tasks they wish to pursue, and do their analytical work within that tool. Since the tools allow standardized extraction of data for additional display, data management, navigation, or additional analysis and commentary, a user can move from tool environment to tool environment to achieve separate tasks (transcription, addition of structured metadata, commentary and notes, etc.).
The end result of this project is a user interface that draws image resources from the participating repositories and user-generated data produced by the participating tools, hosted by each respective participant. New data from any participating node will be automatically added to the interface without the need for human-mediated interaction, leading to a dynamically growing resource. This resource will allow a user to browse a Kalendar and see image, transcription, and commentary data about each entry, or compare across Kalendars to observe clusterings of continuity and variance over the liturgical year depending on location of book use and production, or chronological period. The distributed approach to a standardized text, where variants are of great interest across a large number of disciplines, and which benefits from a broad array of participants providing small bits of detailed data to build up a useful dataset, could serve as a model for further work on other parts of the Book of Hours, or other medieval texts that were copied frequently an reflect changing social, political, or liturgical practices across Western Europe over a period of several hundred years.