XQuery databases for language resources in the IAIA and UyLVs Projects
July 19, 2013, 10:30 | Long Paper, Embassy Regents D
This paper reports on work done in the Interactive Inner Asia (IAIA) and Uyghur Light Verbs (UyLVs) projects [1] on two problems arising in the construction of XML query interfaces for linguistically annotated corpora in Central Asian languages: (1) providing both simple search interfaces for casual users and open-ended interfaces for specialists, without security vulnerabilities; and (2) using XQuery for search patterns involving precedence relations (on sequences of siblings) and not only dominance (containment) relations.
XML query interfaces are not the focus of either project, just means to an end. The immediate purpose of both projects is the study of language contact, language areas, and the development of particular linguistic structures; a broader aim is the creation of annotated corpora useful both for comparative and historical linguistic research and for ethnological, folkloric, literary, historical and other study.
1 Current corpus format and user interfaces
Although the goals of the two projects differ, the IAIA and UyLVs projects share a common corpus format. Transcriptions of audiovisual recordings and transliterations of manuscripts are presented in multiple tiers: one tier holds the text in a practical orthography, one in the International Phonetic Alphabet (IPA); other tiers contain a morphological segmentation, part-of-speech labels, an interlinear gloss, free translations in English, Russian, German, Chinese, and/or Tibetan, and comments (not all tiers are present for all utterances).
In the current version of our XML corpus format (Sperberg-McQueen 2012), a sample Uyghur sentence takes the following form:

Future versions will replace the implicit alignment of the SEG, POS, and ILG tiers with an explicit alignment to simplify validation and searching (Dwyer / Sperberg-McQueen 2013).
2 Sample queries
Simple searches (e.g. for light verbs, coded “LV” in the pos tier) are useful for the project. But linguistically motivated queries easily become complex. Like those of many corpora, our POS tier does not encode grammatical relations (including Subject), so to study the co-occurrence of light and main verbs with the subjects of their sentences, we search for types of noun (tagged N, PN, etc.) in certain positions and with certain predicted inflections, in order to identify subjects. In Uyghur, a subject or agent is likely to be the leftmost uninflected noun (e.g. Bu in the sentence “Bu [Alimdin kelgen xet] PN [Npr-ABL Vi-PST.REL N] 'This is the letter from Alim',”) even when the subject is a relative clause (e.g. xet, in: “[Alimdin kelgen xet] uzun iken. [Npr-ABL V-PST.REL N] AJ COP.indir '[The letter from Alim] seems to be long.')”.
To exclude adjuncts (like after lunch in “After lunch, Mahire took a nap”), which are potentially the leftmost N, we search for the leftmost N (excluding the string "NUM"), and excluding N-*, N(*) POST and then sort the results by the surface form of the matrix verb or light verb.
A third query searches for patterns across different languages in the IAIA project. Both SE Monguor and Baonan have calqued a postposed indefinite article nege~nige ‘one’ from Tibetan zeg ‘one’. We've seen instances of postposed yi-ge (yi ‘one’ (Chinese) + ge ‘classifier’ (Chinese) in the same postnominal position, at least in mjg-se. We might hypothesize that that yige is the Mandarin calque equivalent of the Mongolic nege calque, and that both originate in Tibetan zeg. The presence of yige is thus a good indicator of a strong Mandarin influence on the language. To test the hypothesis, we will want to search the segmentation layer for the morphemes yi and -ge in adjacent positions, or alternatively for adjacent pairs of the POS tags NU-CL.
3 Supporting open-ended queries
The queries above illustrate a common pattern. The first is trivial to express in XPath or XQuery:
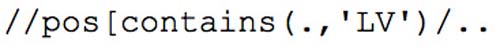
or alternatively
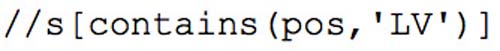
Similar queries will be necessary for other POS tags; the query “Find all sentences containing a morpheme tagged X” (for any POS-tag X) will be useful both to the project team and to casual outside users of the collection.
Not all users will know enough XPath to formulate such queries on the fly, however, so it would be helpful to provide query interfaces for this and similar queries which do not require the use of a query language. The usual solution to this common problem is to make some pre-defined searches available in some fill-in-the-blank or point-and-click interface where users can select a pre-defined query and select its parameters from a list. In our full paper, we will show the search forms in use in the IAIA and UyLVs projects for this kind of canned search.
For intensive use of the collection, however, such fixed-parameter searches will not suffice. As the other queries above illustrate, intensive use of any collection will require new ad-hoc searches, not predefined ones, and arbitrary Boolean combinations of basic searches. How can projects support such open-ended queries?
One easy solution is to allow users to formulate queries in the underlying query language (for these projects, XQuery; in the case of relational data, SQL). Feeding raw user data to a live XQuery interpreter, however, represents a sizable security hole and cannot be advised. [2] We discuss other ways to provide open-ended searches:
- Define an acceptable ('safe') subset of XQuery. If the user input is in that subset, hand it to the XQuery engine for evaluation; otherwise, hand it back to the user for correction (or conclude that the user is an attacker and shut down).
- The safe subset can be checked by:
- a full context-free parser for the subset, or
- regular expressions which capture 'regular approximations' of the subset; we will generate these automatically from the subset definition and execute them with standard regular-expression evaluators.
- Define a new open-ended query language for advanced users, using an ad-hoc character-based syntax, then write (a) a parser for the language, and (b) a translator into XQuery, for communication with the underlying XQuery engine.
- Implement some existing query language (or a subset); candidates include Annis 2 (Zeldes 2012); Arras (Smith 1985); CSS Selectors (); the DynaText query language (EBT 1996), (Silicon Graphics 1995); the ‘extended pointer notation’ of TEI P3 and P4 (ACH/ACL/ALLC 1994), (ACH/ACL/ALLC 2001-2004); the query language of Sara / Xaira (Burnard, n.d.); and subsets of XPath 1.0 or 2.0 (W3C 1999), (W3C 2010).
- Define a query language using an XML syntax, with a user interface defined in XForms to allow the user to formulate complex queries (roughly analogous to the 'query builder' interfaces familiar from search tools like Xaira [Burnard, n.d.] and EXMARaLDA [Schmidt 2010]).
4 Searching on siblings in XQuery
A second class of challenge is illustrated by the third query described above. In building our corpora we have, like many others before us, focused our attention initially on segment-by-segment annotation of the data. We have not built parse trees for our sentences; we are building corpora, not tree banks. Automatic parse-tree generators are widely available for ‘major’ languages, but for the non-standardized, unwritten, and ‘non-major’ languages at the center of our work, such tools will become possible only as a result of projects like ours. In the absence of XML representations of full parse trees, subjects, agents, etc., our users will need to search for grammatical relations by using surrogates. As illustrated above, a search for a subject will need to be reformulated as a search for a particular pattern in the sequence of anotated morphemes in a sentence.
Sequence searching is a particular challenge for linguistic resources. XQuery engines are typically very good at building indexes for Boolean combinations of context-sensitive searches (find X within Y where Z and (W or V) ...), but sequence searches are much trickier to support. By a 'sequence search' we mean (for example) a search for morphemes M1, M2, M3 in that order, with M1 matching this pattern, M2 matching that pattern, and M3 the other pattern, and M1 adjacent to M2 and M3 anywhere later in the same utterance. Some of our work will focus on whether we can construct indexes manually to help make such queries faster or more convenient. Sequence searches are likely to be of interest for corpus linguists in any area, as well as for people interested in tight control of full-text phrase searches.
In the full paper, we survey some existing work in this area (e.g. in the Prague Markup Language [Pajas 2010] and in corpus search tools like EXAKT [Schmidt 2010] or Sara and Xaira [Burnard, n.d.]), and describe our work on supporting sequence pattern searches in XQuery. In so doing, we also illustrate the balance between the inclusion of syntactic annotation and ease of querying.
References
Notes
1. The IAIA and UyLVs projects are supported by the U.S. National Science Foundation (NSF-BCS 1065524, 1053152). Much of the data for IAIA stems from earlier work sponsored by a Fulbright-Hays and a Volkswagen Foundation DOBES grant.
2. The problem is that SQL injection is widely known as an attack vector for machines on the open net; XQuery injection is also possible and has been documented (van der Vlist 2011).